Как перевести отсканированный документ в word. как отсканированный документ перевести в формат word
Содержание:
Как перенести текст с фото в Word онлайн: 5 сервисов
Прибегают к ним, как правило, для переноса текста с фото в Word в небольших объемах, а также тогда, когда операция носит разовый характер. Подавляющее большинство таких сервисов являются условно-бесплатными, при этом в бесплатном режиме они ограничивают функционал — устанавливают лимиты на объем текста, количество языков, требуют обязательной регистрации и так далее.
Convertio
Хороший сервис для перевода текста с фото в Word, понимает несколько десятков языков, работает с PDF и популярными форматами растровых изображений, позволяет сканировать до 10 страниц в бесплатном режиме. Результат сканирования может быть сохранен в 9 форматов, включая Word.
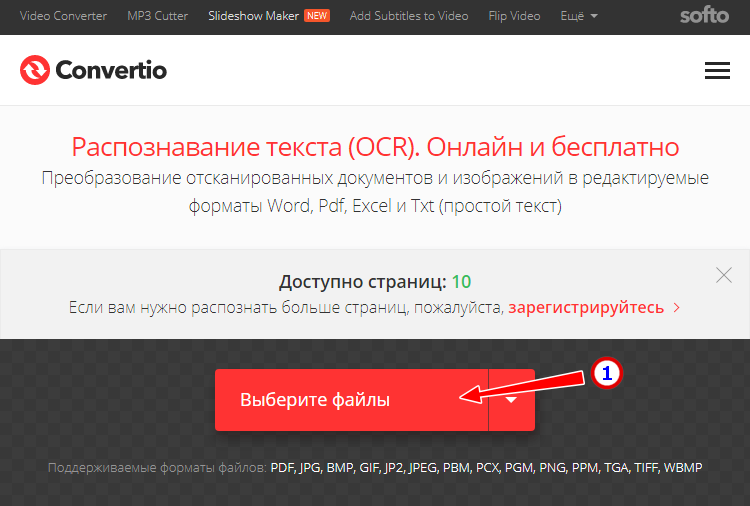
- На странице сервиса нажмите «Выберите файлы» и укажите изображение на диске. Можно последовательно добавить еще 9 файлов;
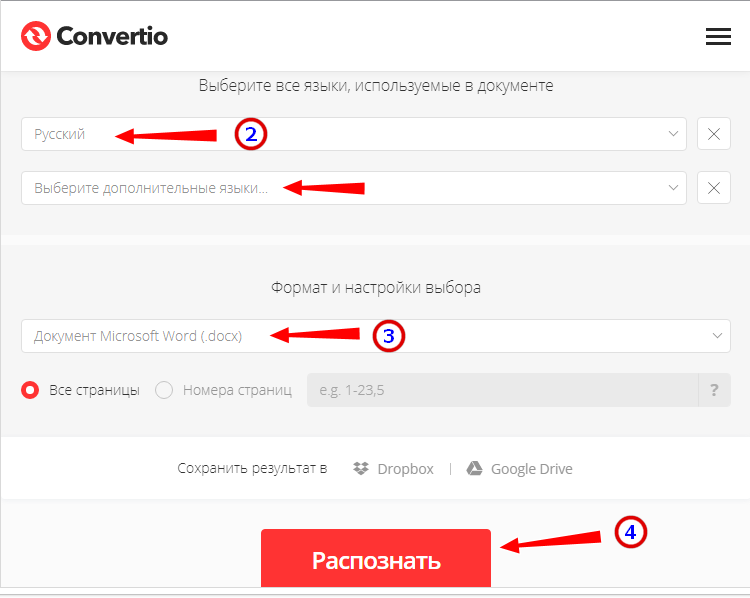
- Укажите распознаваемый язык (по умолчанию русский) и формат сохранения;
- Нажмите «Распознать», а затем появившуюся чуть выше кнопку «Скачать».
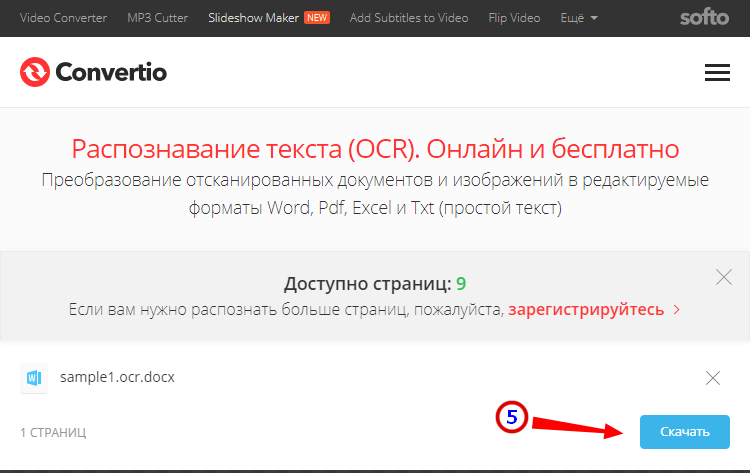
- Не требует обязательной регистрации.
- Загрузка с Dropbox, Google Drive и по URL.
Плохо работает с изображениями с многоцветным фоном.
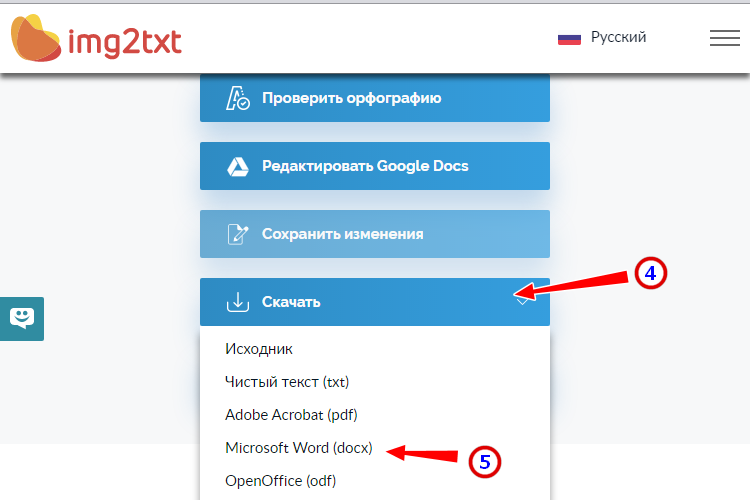
Img2txt
Бесплатный онлайн-сканер текста с фото для Word, поддерживает работу с растровыми изображениями и PDF-документами размером не более 8 Мб.
- Выберите файл нажатием одноименной кнопки;
- Укажите язык распознаваемого текста;
- Нажмите «Загрузить» и дождитесь результата;
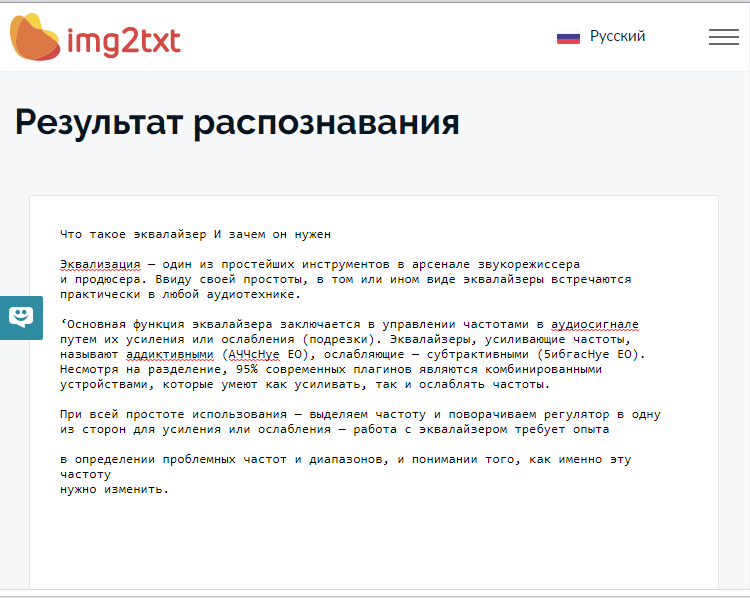
- Прокрутите страницу немного вниз, нажмите «Скачать» и укажите формат Word.
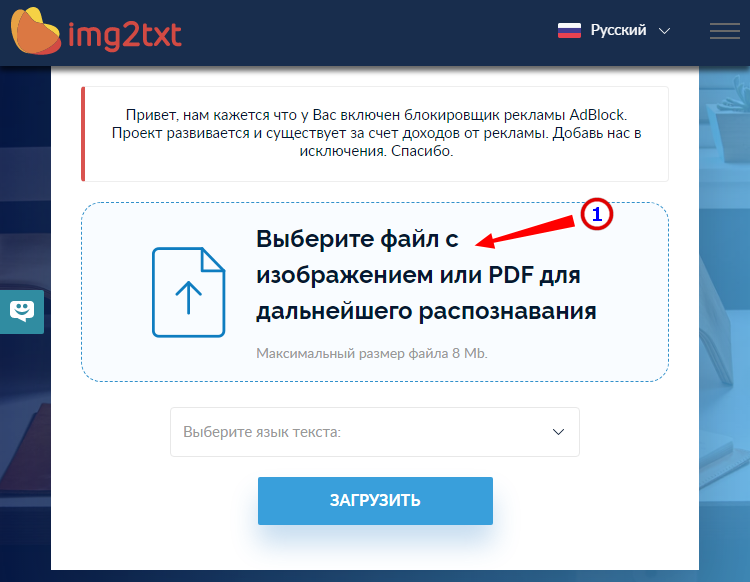
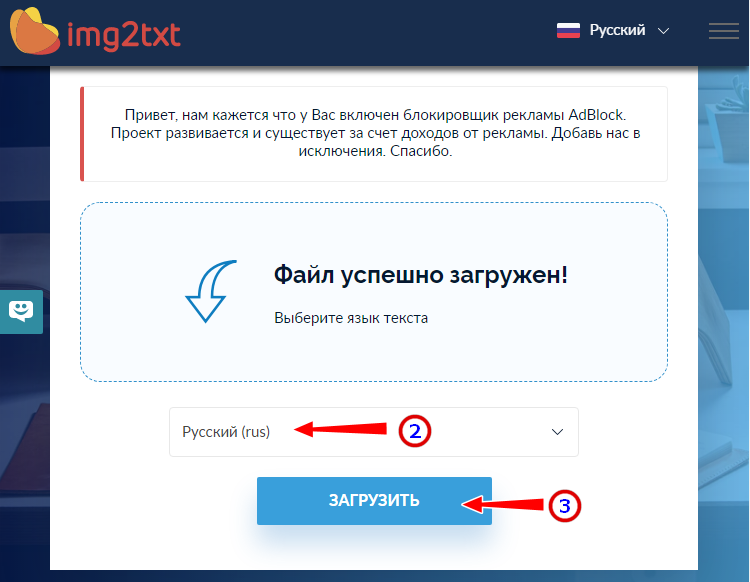
- Совершенно бесплатен и не требует регистрации.
- Предпросмотр результатов конвертации текста с фото в Word.
- Может распознавать текст даже из картинок с цветным фоном, но не исключены и ошибки.
Размер фото не должен превышать 8 Мб.
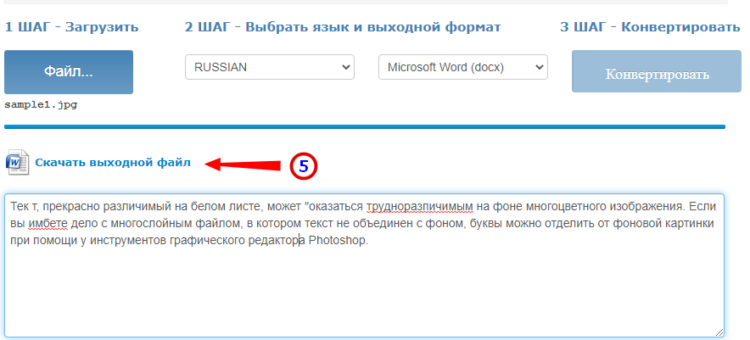
Online OCR
Этот бесплатный сервис позиционируется как конвертер PDF в Word с оптическим распознаванием, но с таким же успехом он может быть использован как преобразователь текста с фото в Word в режиме онлайн. Без регистрации позволяет вытащить из фото текст в Word до 15 раз в час.
- Нажмите кнопку «Файл» и выберите на жестком диске фото;
- Укажите язык распознавания и выходной формат файла DOСX;
- Нажмите «Конвертировать», отредактируйте, если потребуется, текст в поле предпросмотра и скачайте выходной файл.


- Регистрироваться необязательно.
- Распознаёт текст с картинок с цветным фоном с выводом в область предпросмотра.
- Поддерживает распознавание текста с фото в Word в пакетном режиме.
- При извлечении текста из цветного фото текст иногда приходится копировать из области предпросмотра, так как при сохранении даже хорошо распознанного текста в Word в файл вставляется картинка-исходник.
- Разрешение картинки должно быть не менее 200 DPI, в противном случает текст будет содержать много ошибок.
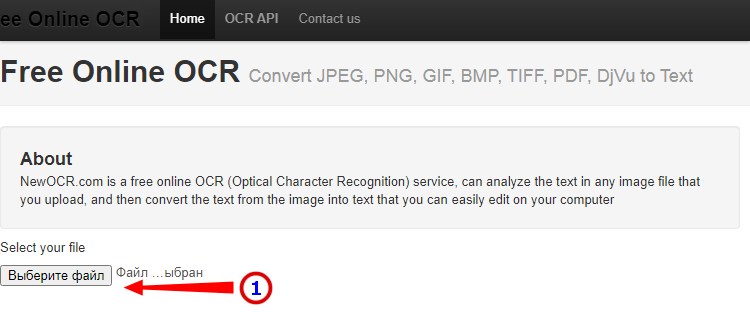
Free Online OCR
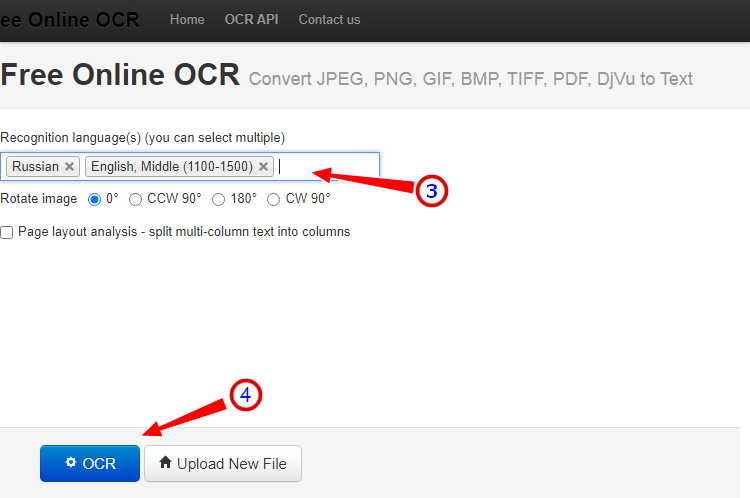
Неказистый на вид, но достаточно неплохой англоязычный сервис, позволяющий распознать текст с фото в Word онлайн. В отличие от аналогичных ресурсов, Free Online OCR умеет автоматически определять язык текста на изображении, поддерживается добавление дополнительных локализаций на случай, если фото содержит текст двух языков. Из дополнительных возможностей стоит отметить поворот картинки на 180°, 90° вправо/влево, а также разделение многоколоночного текста на столбцы.
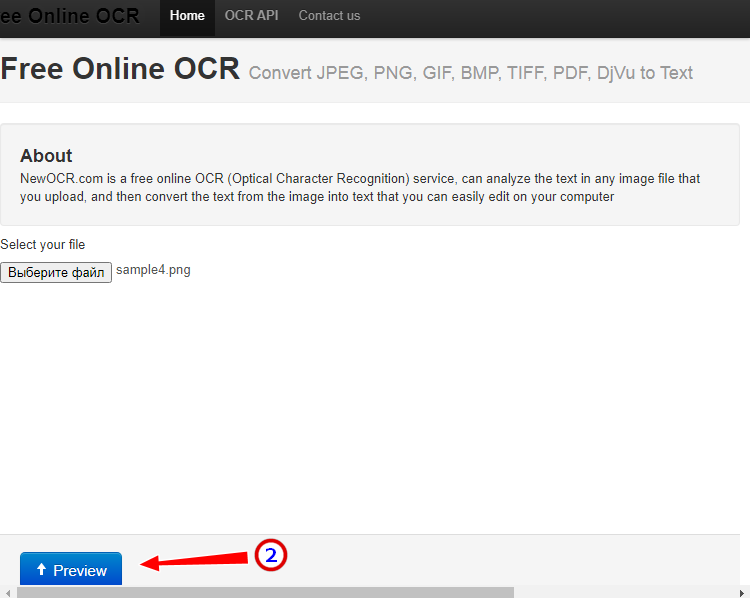
- Нажмите кнопку выбора файла, а когда его имя появится рядом с кнопкой, нажмите «Preview»;
- Убедитесь, что программа точно определила язык, если нужно, добавьте кликом по полю «Recognition language(s) (you can select multiple)» второй язык.
- Нажмите кнопку «OCR» для запуска процедуры распознавания.
- Проверьте корректность распознавания, в меню выберите Download → DOC.
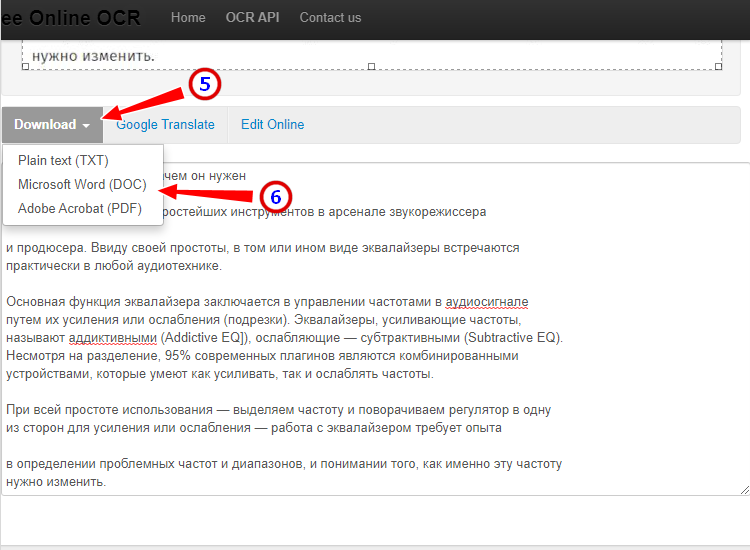
- Прост и удобен.
- Наличие дополнительных опций.
- Имеется возможность выбрать конкретный участок изображения.
- Нет поддержки пакетного режима.
- Иногда игнорирует второй язык.
- Не поддерживает конвертирование в DOCX.
ABBYY FineReader Online
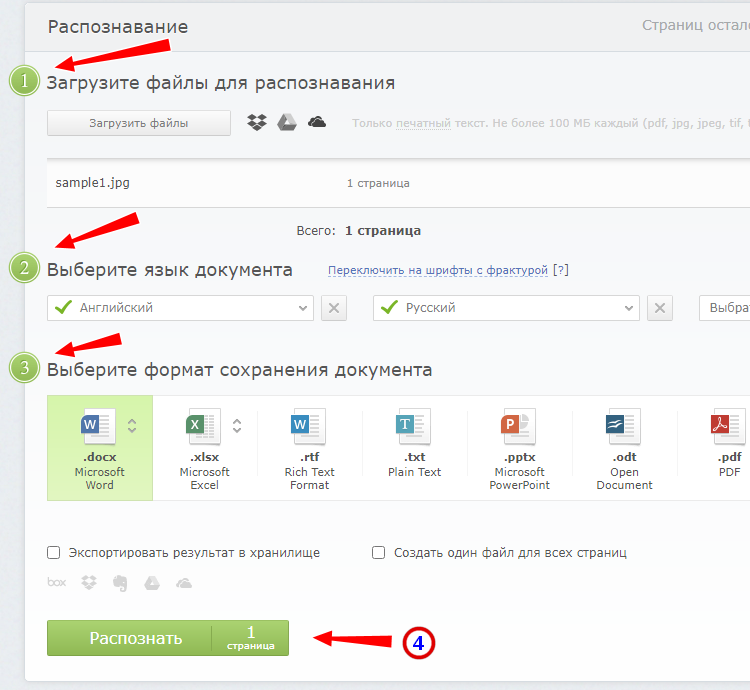
Наиболее известный и качественный сервис, позволяющий выполнить распознавание текста с фото в Word онлайн. Отличается функциональностью, поддержкой множества языков и девяти форматов, загрузкой файлов с облачных хранилищ, а также сохранением результатов в облачные хранилища.
- Зайдите на сервис с помощью учетной записи Facebook, Google или Microsoft;
- Нажатием одноименной кнопки загрузите изображения с текстом;
- Выберите язык документа и формат сохранения;
- Нажмите «Распознать»;
- Скачайте готовый файл на следующей странице.

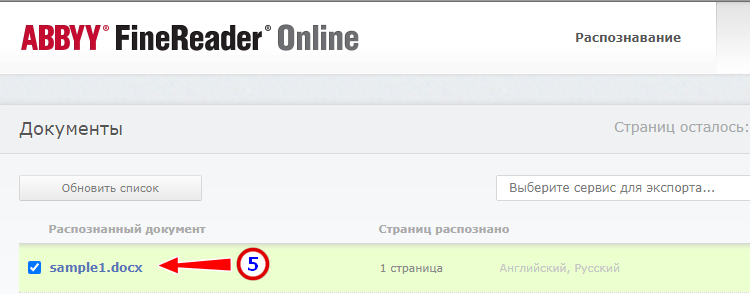
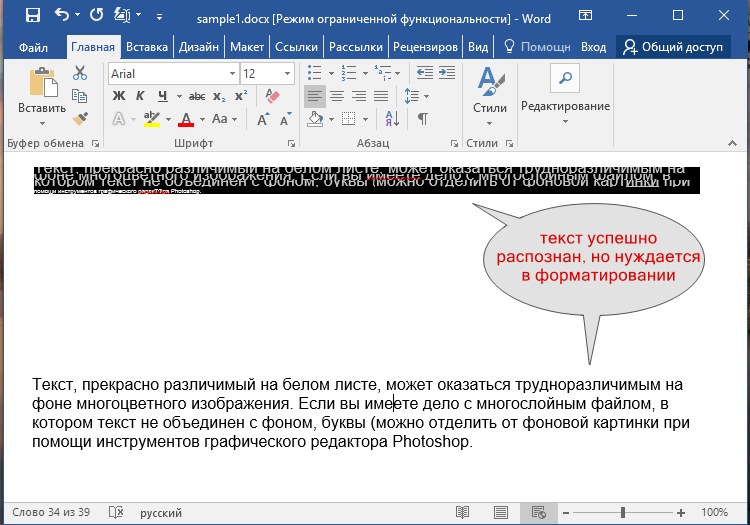
- Отличное качество распознавания.
- Пакетный режим.
- Требуется обязательная регистрация.
- В бесплатном режиме можно обработать не более 12 документов.
- Текст в документах Word может нуждаться в дополнительном форматировании.
Сканирование в Microsoft Word
С помощью стартового окна вы можете создавать документы Word при помощи сканера или фотоаппарата.
- На закладке Сканировать нажмите Сканировать в Microsoft Word.
- Выберите устройство и задайте параметры сканирования.
- Нажмите кнопку Просмотр или в любом месте области сканирования.
- Просмотрите полученное изображение, при необходимости измените параметры и снова нажмите Просмотр.
- Укажите настройки выбранного формата.Внешний вид и свойства полученного документа будут зависеть от выбранных вами настроек.
- Сохранять форматирование. Выбор режима сохранения форматирования зависит от того, как вы будете использовать созданный документ в дальнейшем:
- Точная копияВозможность редактирования выходного документа ограничена, но при этом максимально точно сохраняется внешний вид документа.
- Редактируемая копияОформление выходного документа может незначительно отличаться от оригинала. Полученный документ легко редактируется.
- Форматированный текстСохраняются только шрифты, их размеры и начертание, разбиение на абзацы. Полученный документ содержит сплошной текст, записанный в одну колонку.
- Простой текстСохраняется только разбиение на абзацы. Весь текст форматируется одним шрифтом и располагается в одной колонке.
Языки распознавания — необходимо правильно указать языки документа. Подробнее см. «Языки распознавания».
Сохранять картинки — отметьте эту опцию, если вы хотите сохранять иллюстрации в полученном документе.
Сохранять колонтитулы и номера страниц — в полученном документе будут сохранены колонтитулы и номера страниц.
Настройки предобработки изображений… — вы можете задать настройки обработки файлов изображений, включая определение ориентации страницы и автоматическую обработку изображений. Эти настройки позволяют значительно улучшить исходное изображение и получить более точные результаты конвертации. Подробнее см. «Параметры обработки изображений».
Другие настройки… — позволяет открыть Настройки форматов на закладке DOC(X)/RTF/ODT диалога Настройки (меню Инструменты > Настройки…) и задать дополнительные настройки.
Нажмите Сканировать в Microsoft Word.
После запуска на экране появится панель выполнения задачи, содержащая индикатор выполнения и подсказки.
После завершения сканирования текущей страницы на экране появится диалог выбора дальнейшего действия. Нажмите Сканировать снова, чтобы запустить процесс сканирования следующих страниц с текущими настройками, или Завершить сканирование, чтобы закрыть диалог.
Укажите папку для сохранения полученного Word-документа.
По завершении задачи документ Microsoft Word будет создан в указанной папке. Кроме того, все изображения будут добавлены в OCR-редактор и доступны для обработки.
help.abbyy.com


Загрузка и сканирование

Для запуска процесса:



Данная программа автоматом выделит фрагменты документа, рисунки и таблицы, при необходимости повернет сканированный текст по нужному направлению. После завершения сканирования, в данной программе требуется выбрать язык для расшифровки написанного.Выбрать его можно в выпадающем окне «Язык документа», если загруженный скан будет написан на нескольких иностранных языках – следует выбрать автоматический режим.


OCR по шагам
Предобработка
Чем лучше качество исходного текста на бумажном носителе, тем лучше будет качество распознавания. А вот старый шрифт, пятна от кофе или чернил, заломы бумаги понижают шансы. Большинство современных OCR-программ сканируют страницу, распознают текст, а затем сканируют следующую страницу. Первый этап распознавания заключается в создании копии черно-белого цвета или в оттенках серого. Если исходное отсканированное изображение идеально, то все черное — это символы, а все белое — фон.
Распознавание
Хорошие OCR-программы автоматически отмечают трудные элементы структуры страницы — колонки, таблицы и картинки. Все OCR-программы распознают текст последовательно, символ за символом, словом за словом и строчка за строчкой. Сначала OCR-программа объединяет пиксели в возможные буквы, а буквы — в возможные слова. Затем система сопоставляет варианты слов со словарем. Если слово найдено, оно отмечается как распознанное. Если слово не найдено, программа предоставляет наиболее вероятный вариант и, соответственно, качество распознавания будет не таким высоким.
Постобработка
Некоторые программы дают возможность просмотреть и исправить ошибки на каждой странице. Для этого они используют встроенную проверку орфографии и выделяют неверно написанные слова, что может указывать на неправильное распознавание. Продвинутые OCR-программы используют так называемый метод поиска соседа, чтобы найти слова, которые часто встречаются рядом. Этот метод позволяет исправить неверно распознанное словосочетание «тающая собака» на «лающая собака».
Кроме того, некоторые проекты, которые занимаются оцифровкой и распознаванием текстов, прибегают к помощи волонтеров: распознанные тексты выкладываются в открытый доступ для вычитки и проверки ошибок распознавания.
Особые случаи
Для высокой точности распознавания исторического текста с необычными графическими символами, отличающимися от современных шрифтов, необходимо извлечь соответствующие изображения из документов. Для языков с небольшим набором символов это можно сделать вручную, но для языков со сложными системами письменности (например, иероглифических) ручной сбор этих данных нецелесообразен.
Для распознавания исторических китайских текстов требуется внести в OCR-программу как минимум 3000 символов, которые имеют разную частотность. Если для распознавания исторических английских текстов достаточно ручной разметки нескольких десятков страниц, то аналогичный процесс для китайского языка потребует анализа десятков тысяч страниц.В то же время многие исторические варианты китайской письменности имеют высокую степень сходства с современным письмом, поэтому модели распознавания символов, обученные на современных данных, часто могут давать приемлемые результаты на исторических данных, хоть и со сниженной точностью. Этот факт вместе с использованием корпусов позволяет создать систему для распознавания исторических китайских текстов. Для этого исследователь Д. Стеджен (Donald Sturgeon) из Гарварда обработал два корпуса: корпус транскрибированных исторических документов и корпус отсканированных документов желаемого стиля.
После предварительной обработки изображений и этапов сегментации символов процедура извлечения обучающих данных состояла из: 1) применения модели распознавания символов, обученной исключительно на современных документах, к историческим документам для получения промежуточного результата оптического распознавания с низкой точностью; 2) использование этого промежуточного результата для соотнесения изображения с его вероятной транскрипцией; 3) извлечение изображений размеченных символов на основе этого соотнесения; 4) выбор из размеченных символов подходящих обучающих примеров.Полученные данные могут использоваться без проверки для обучения новой модели распознавания символов, позволяющей достичь более высокой точности на аналогичном материале.
Сканер, документ, FineReader
Говоря о функциональности программы для распознания текста, отдельно хотелось бы сказать о возможности работы с различной оргтехникой и гаджетами. Так, установка FineReader на жесткий диск девайса снимает перед пользователем вопрос — как отсканировать документ на компьютер?
Дело в том, что не всегда хватает одного драйвера устройства для работы какой-либо оргтехники. Сканер не исключение. Как правило, в комплекте с ним прилагается диск с программой, которая и обеспечивает работу с устройством. Но функциональность такого ПО часто ограничена.
FineReader совместим со всеми сканерами известных производителей. Установив его на свой компьютер, пользователь может использовать эту программу в качестве ПО для работы с изображениями. Документы можно просто сканировать и сохранять; задать команду оставлять отснятое изображение сразу в «Ворд»; создавать PDF-файлы. Из них же переводить тексты в текстовой редактор Microsoft Office. В итоге одна небольшая программа с легкостью справляется с такой задачей, как отсканировать документ на компьютер, и может заменить громоздкие графические инструменты, при этом обеспечив бесперебойную работу целого офиса.
Здравствуйте. Сегодня я расскажу, как сканировать текст в документ Word
. Зачем это нужно делать? Ответ очевиден, для дальнейшего редактирования текста. Ведь изображение не так просто будет отредактировать. Что лучше использовать, программы или онлайн сервис для перевода сканированного текста в документ Word? Об этом я расскажу ниже в статье.
Для того что бы максимально ускорить и упростить задачу
, я искал сайты, на которых онлайн можно конвертировать сканированный документ в формат Word. Для этого мне пришлось сначала сканировать, а затем уже конвертировать. Сразу скажу, что многие сайты ограничивают количество переводов в Word, а что бы не ограничено конвертировать нужно заплатить. Мне удалось найти пару сайтов, которые не ограничено решают эту задачу, но делится не буду, так какконвертировать сканированный текст в Word онлайн оказалось пустой тратой времени.Процент распознания текста очень низкий , проще было бы перепечатать документ с нуля.
В таком случае, если онлайн инструменты на данный момент плохо переводят сканированный документ в Word
, то как же сделать это максимально качественно? Читайте об этом дальше в статье, я приведу понятную инструкцию.
Погулив ещё несколько минут, нашел программу, называется ABBYY FineReader Professional. Наверняка Вы уже слышали про неё. Скачал её тут https://nnm-club.me/forum/viewtopic.php?t=851116
, легко устанавливается и отлично работает.
ABBYY FineReader может перевести сканированные документы не только в Word, но и в PDF и многие другие текстовые и журнальные форматы.
Пользоваться ею очень просто. Устанавливаете и запускаете. На мониторе должны увидеть вот такое окно, как ниже не скриншоте.
Тут ничего сложного, интуитивно понятно, что нужно нажать в нашем случае на «Сканировать в Microsoft Word»
. Затем увидим окно настроек сканирования, в котором можно ничего не менять.
Поставим программе не простую задачу — сканировать и распознать страницу книги
. Кладем книгу или любой другой документ на сканер и нажимаем сканировать. Программа начинает сканирование, а затем должна автоматически распознать документ.Если автоматического распознания не произошло , то нажмите правой кнопкой на сканированный документ и нажмите «Распознать». Ниже на скриншоте видно какой результат получился у меня.
Далее нажимаете на значок Word вверху
и документ сохранится в текстовый формат документа Microsoft Word. Разумеется нужно учитывать, что распознанный текст нужно обязательно перечитывать, ведь в любом случае возможны ошибки.
Задавайте вопросы, пишите комментарии
Спасибо за внимание
Работа с документом в FineReader
FineReader – наиболее актуальная программа автоматического распознавания отсканированного документа, она была создана российскими программистами. Ее главными достоинствами можно считать возможность поддерживания большого количества языков, среди которых имеются даже самые древние.
Помимо этого в этой программе допускается пакетная обработка многостраничного текста.
Ее преимуществами также можно назвать:
- распознавание текста, набранного различными шрифтами, в том числе и рукописного написания;
- корректное распознавание картинок и таблиц в файле;
-
распознавание некачественных текстов;
- удобный перевод текста документа в файл Word.
Пробную версию данной программы можно загрузить на официальном сайте, ее единственный недостаток заключается в том, что там установлено ограничение. Бесплатно можно обработать не более пятидесяти отсканированных страниц текста.
Полная версия программы стоит около пятидесяти долларов, на ней подобное ограничение отсутствует.
Загрузка и сканирование
Самым первым этапом работы в FineReader является загрузка и сканирование файла.
Для запуска процесса:
- в меню нужно выбрать окно «Сканирование»;
-
спустя некоторое время программа обработает документ и перенесет его на экран программы в виде изображения;
- далее необходимо будет расшифровать сканированный текст;
перенести его в формат файла Ворд, а затем сохранить.
Данная программа автоматом выделит фрагменты документа, рисунки и таблицы, при необходимости повернет сканированный текст по нужному направлению. После завершения сканирования, в данной программе требуется выбрать язык для расшифровки написанного.
Выбрать его можно в выпадающем окне «Язык документа», если загруженный скан будет написан на нескольких иностранных языках – следует выбрать автоматический режим.
Удаление форматирования из документа
Сейчас мы более подробно разберем, как можно отредактировать отсканированный документ в программе FineReader. На представленном изображении таблицы, картинки и тексты будут отличаться разными цветами.
Данные области расшифровываются автоматически в зависимости от своего типа. В дальнейшем работать с ними в данной программе позволяет раздел под названием «Проверьте области», он располагается в правом окне FineReader.
Для удаления какой-либо области из документа необходимо выбрать в выпадающем меню кнопку «Удалить область», а затем можно будет щелкать мышкой по тем фрагментам, которые следует удалить.
Допускается уничтожение всех картинок и таблиц, можно оставить только лишь нужный для распознавания и дальнейшего сохранения текст.
Редактирование
Чтобы выделить какую-либо область требуется выполнить следующие действия:
- кликнуть мышью по кнопке «Выделить область Текст»;
- нажатой левой кнопкой обвести границы текстового блока в рамку.
А чтобы выделить картинку или таблицу потребуется:
- выбрать кнопку «Выделить область Картинка» или же «Выделить область Таблица»;
- точно также обвести границы блока также левой кнопкой мыши.
Многих пользователей интересует, можно ли в программе FineReader поменять размеры выделенного фрагмента. Это вполне реально, необходимо лишь щелкнуть мышью по нужному фрагменту, навести курсор на его границу до возникновения специального курсива.
Именно на нее требуется нажать левой кнопкой мыши и, удерживая, менять размер, перемещая мышь в большую или меньшую сторону.
Конвертирование в формат Word
После того, как все области будут выделены и отредактированы так, как нужно, можно будет приступить к распознаванию написанного документа и его сохранению в формате Word. Для проведения подобной процедуры следует нажать кнопку «Конвертировать» в меню программы.
Пользователю нужно будет подождать некоторое количество времени, после чего он сможет просмотреть результаты проделанной работы. Для сохранения текста необходимо ввести имя файла, выбрать для него место и формат сохранения.
Для создания файла в формате Microsoft Word нужно выбрать в окне «Rich Text Format (*.rtf)».
ABBYY Screenshot Reader
Работает Screenshot Reader в двух режимах – создании скриншотов и распознавании текста с экрана. Если вам нужно второе, сначала просто нажимаете на комбинацию клавиш, выбираете язык и принцип захвата, выделяете область, подтверждаете действие и ждете несколько секунд. Полученные данные сохранятся в выбранном вами формате. В приложение встроен словарь и переводчик, также другие полезные функции от компании ABBYY.
По умолчанию сервис распознает тексты на 5 языках – английском, русском, русско-английском, французском и немецком. Есть возможность добавления других языковых пакетов.
Плюсы
- Быстрый запуск посредством нажатия на комбинацию клавиш.
- Встроенная функция перевода и проверки орфографии.
- Есть запись экрана с функцией отсрочки.
- Распознавание текста с любого окна, даже в защищенном режиме.
- Создание скрина с любой, даже защищенной области экрана.
- Сохранение в нескольких форматах – rtf, txt, doc или xls.
Минусы
- Для копирования полученных данных в редактор нужно выделять материал вручную.
- Открыть файл через этот сервис не получится – только ручной захват экрана.
- Приложение не бесплатное. Есть бессрочная лицензия, но она стоит 1490 рублей. А срок действия пробной версии составляет всего лишь 7 дней, также в ней есть ограничение до 100 страниц.
Другие программы
Нижеприведенные утилиты практически ничем не отличаются от официального софта. Разница только в некоторых программах, которые призваны делать сканы в какой-то определенный формат, например, в PDF.
- FineReader. Софт платный, но есть пробная «free» версия и онлайн-инструмент. Доступна для работы с множеством языков. Кроме простого сканирования может распознавать отсканированный текст и переводить документ в формат для дальнейшего редактирования.
- WinScan2PDF. У бесплатной программы узкая направленность – сканировать в формат PDF. Чаще всего используется при работе в сети.
- RiDoc. Пригодится тем, кому часто необходимо получать сканированные документы в самых разных форматах. Если такой нужды нет, тогда проще пользоваться стандартным средством или другими более простыми аналогами.
- VueScan. По функциональности похожа на все предыдущие программы. Есть встроенный преобразователь изображения в текст.
- CuneiForm. Распознает текст и таблицы со сканов, имеет широкий набор настроек для регулирования конечного качества скана. Скачивается с интернета бесплатно.
- ScanLine. Небольшая и простая в применении утилита. Содержит минимум настроек, получить скан можно буквально в пару кликов.
https://youtube.com/watch?v=jpVr1L7xRko
Как это работает
Оптическое распознавание текста (OCR — Optical Character Recognition) – это возможность преобразовать текст из графического вида (фото, скан, pdf) в обычный формат. Преобразованный текст можно редактировать. Любая растровая картинка состоит из точек. Программное обеспечение для распознавания выделяет на картинке буквы и переводит их в текст. Происходит анализ структуры документа. Выделяются текстовые блоки. Затем строятся линии, которые делятся на слова, а далее на символы. Каждый символ сравнивается с шаблонами. После чего строятся гипотезы, что это за символ. Исходя их них, ПО анализирует разные варианты разбиения строк на слова, а слова на символы. Количество таких гипотез огромно. В конец концов программа принимает решение и выдает текст.
Как сканировать в word 2010?
В этой статье мы подробно рассмотрим, как сканировать в word 2010 с возможностью последующего редактирования текста и изображения.
Выполняем сканирование
- Открываем настройки сканера – Пуск — «Устройства и принтеры» — иконка с подключенным сканирующим оборудованием.
- Кладем документ – текст или фото – изображением вниз, чтобы края не выходили за границы рабочей зоны сканера.
- Крышку сканера плотно прижимаем к документу. Это делается для того, чтобы исключить попадание света на сканируемую зону.
- Устанавливаем разрешение. Помните, чем оно выше, тем лучше качество изображения. Для фото и картинок можно установить 600, для текстовых документов вполне хватит 400-500. Жмем «Сканировать» и указываем место, куда сохранить готовый файл.
Сохраняем сканирование в Word 2010
Откройте документ Word 2010. В верхнем меню выберите функцию «Вставка», опция «Рисунки».
В открывшемся окошке выберите папку, куда вы сохраняли отсканированный документ. Затем выберите файл и нажмите кнопку «Вставить».
Сканирование с программой RiDoc
Это программное обеспечение RiDoc позволяет сохранить сканированный файл в Word 2010. Скачиваем и устанавливаем программу на компьютер. Открываем ее и начинаем сканировать:
- В верхнем меню щелкаем на функцию «Сканер» и выбираем подключенное устройство.
- Для сохранения документа в ворде выбираем кнопочку «MS Word».
Теперь склеиваем отсканированные изображения с помощью функции «Склейка» на панели задач.
После нажимаем «PDF» и сохраняем полученный документ на рабочий стол или в удобную папку.
Сканирование с Adobe FineReader.
Программа считается самой удобной для сканирования и последующего распознавания документов.
Запустите программу FineReader на своем ПК. Нажмите «Файл», дальше «Сканировать». Если у вас еже есть отсканированная картинка, тогда ее достаточно просто открыть, распознать и дальше уже редактировать.
Выберите «Черно-белый рисунок и текст», если для вас приоритетным является именно текстовый документ.
На экране появится отсканированное изображение, где нужно выбрать необходимые участки и указать их тип – текст, картинка или таблица.
Далее кликаем по выделенному блоку и жмем «Распознать». В результате справа появится текст, который можно редактировать.
Статья о том, как сканировать в word 2010, написана при поддержке специалистов копировального центра Printside.ru
printside.ru
Подбиваем итоги
Наконец-то мой компьютер задышит спокойно! Я без сожаления удалил все десктопные программы для перевода документов из ПДФ в Ворд и твёрдо решил использовать исключительно онлайн-сервисы – они бесплатны, запускаются без регистрации и дают отличные результаты. Мой фаворит – сервис Pdf.io, простая, эффективная и симпатичная программа.
Впрочем, онлайн сервисы подходят скорее для домашнего использования и конвертации небольшого количества документов. Если распознавать тексты вам приходится постоянно (например, по долгу службы), не жалейте денег – купите полную версию ABBYY FineReader. Лучше для десктопа до сих пор ничего не придумали.