Кодировка windows 1251 в сайтостроении
Содержание:
- Введение
- Сложные решения
- Где указать кодировку сайта
- Конфликт кодировок
- Как сменить кодировку в консоли windows?
- Спасшая статья:
- Неправильная кодировка HTML страниц
- Кодировки стандарта UNICODE
- Таблица кодов символов Windows-1251
- Как исправить иероглифы Windows 10 путем изменения кодовых страниц
- Таблицы кодировок [ править ]
- Казахский вариант
- Faster — многофункциональный ускоритель работы программиста 1С и других языков программирования Промо
- Особенности
- Немного теории
- Пометка порядка байтов
- Базовая таблица кодировки ASCII
- Преобразование кодовой страницы
Введение
Консольные приложения до сих пор остаются наиболее востребованным видом приложений, большинство разработчиков оттачивают архитектуру и бизнес-логику именно в консоли. При этом они нередко сталкиваются с проблемой локализации — русский текст, который вполне адекватно отражается в исходном файле, при выводе на консоль приобретает вид т.н. «кракозябр».
В целом, локализация консоли Windows при наличии соответствующего языкового пакета не представляется сложной. Тем не менее, полное и однозначное решение этой проблемы, в сущности, до сих пор не найдено. Причина этого, главным образом, кроется в самой природе консоли, которая, являясь компонентом системы, реализованным статическим классом System.Console, предоставляет свои методы приложению через системные программы-оболочки, такие как командная строка или командный процессор (cmd.exe), PowerShell, Terminal и другие. По сути, консоль находится под двойным управлением — приложения и оболочки, что является потенциально конфликтной ситуацией, в первую очередь в части использования кодировок.
Данный материал не предлагает строгий алгоритм действий, а направлен на описание узловых проблем, с которыми неизбежно сталкивается разработчик локализованного консольного приложения, а также некоторые возможные пути их разрешения. Предполагается, что это позволит разработчику сформировать стратегию работы с локализованной консолью и эффективно реализовать существующие технические возможности, большая часть которых хорошо описана и здесь опущена.
Сложные решения
К этим решениям стоит переходить, если проблема никак отказывается уходить и продолжает досаждать. Иероглифы вместо русских букв устройство печатает по причинам, которые будут разобраны ниже.
Дело может быть в системных файлах. Их восстановление может избавить от проблемы.
Открываем командную строку от имени администратора. Вбиваем команду «sfc /scannow» и жмём «Ввод».

Команда «sfc /scannow»
Ждём несколько минут или секунд. Затем проверяем, решилась ли проблема.
Часто такая ошибка появляется из-за драйверов. Принтер печатает иероглифы, поскольку драйверы неправильные или дают сбои. Поэтому можно попробовать их переустановить. Для этого:
Во вкладке Панели управления «Оборудование и звук» находим наш принтер.

Вкладка «Оборудование и звук»
- Нажимаем ПКМ, выбираем «Удалить устройство».
- В «Программах и компонентах» удаляем все программы, связанные с работой нашего аппарата.
- После удаления находим диск, который идёт вместе с устройством печати. Снего заново устанавливаем все необходимые программы и драйверы.
Если диска у вас нет, то Windows 7 или старше, как правило, сама предлагает установить необходимые драйверы, если заново подключить принтер к компьютеру. Если этого не произошло, то стоит зайти на сайт компании-производителя и скачать необходимое ПО самостоятельно.
Проверьте компьютер антивирусом. Причина может крыться во вредоносном ПО.
Вот основные способы разрешения этой проблемы. Как правило, можно ограничиться простыми действиями, поскольку эта ошибка то появляется, то исчезает сама собой.
Где указать кодировку сайта
Если проблема возникла на вашем сайте, способ исправления зависит от вида сайта. Для одностраничника достаточно указать кодировку в мета-теге страницы, а для большого сайта есть разные варианты:
- кодировка в мета-теге;
- кодировка в .htaccess;
- кодировка документа;
- кодировка в базе данных MySQL.
Кодировка в мета-теге
Добавьте указание кодировки в head файла шаблона сайта.
При создании документа HTML укажите тег meta в начале в блоке head. Некоторые браузеры могут не распознать указание кодировки, если оно будет ниже.
Мета-тег может выглядеть так:
или так:
В HTML5 они эквивалентны.
Тег кодировки в HTML
В темах WordPress обычно тег «charset» с кодировкой указан по умолчанию, но лучше проверить.
Кодировка в файле httpd.conf
Инструкции для сервера находятся в файле httpd.conf, обычно его можно найти на пути «/usr/local/apache/conf/».
Если вам нужно сменить кодировку Windows-1251 на UTF-8, замените строчку «AddDefaultCharset windows-1251» на «AddDefaultCharset utf-8».
Убедитесь, что сервер не передает HTTP-заголовки с конфликтующими кодировками.
Кодировка в .htaccess
Добавьте кодировку в файл .htaccess:
- Откройте панель управления хостингом.
- Перейдите в корневую папку сайта.
- В файле .htaccess добавьте в самое начало код:
- для указания кодировки UTF-8 — AddDefaultCharset UTF-8;
- для указания кодировки Windows-1251 — AddDefaultCharset WINDOWS-1251.
- Перейдите на сайт и очистите кэш браузера.
Кодировка документа
Готовые файлы HTML важно сохранять в нужной кодировке сайта. Узнать текущую кодировку файла можно через Notepad++: откройте файл и зайдите в «Encoding»
Меняется она там же: чтобы сменить кодировку на UTF-8, выберите «Convert to UTF-8 without BOOM». Нужно выбрать «без BOOM», чтобы не было пустых символов.
Кодировка Базы данных
Выбирайте нужную кодировку сразу при создании базы данных. Распространенный вариант — «UTF-8 general ci».
Где менять кодировку у БД:
- Кликните по названию нужной базы в утилите управления БД phpMyAdmin и откройте ее.
- Кликните на раздел «Операции»:
- Введите нужную кодировку для базы данных MySQL:
- Перейдите на сайт и очистите кэш.
С новой БД проще, но если вы меняете кодировку у существующей базы, то у созданных таблиц и колонок заданы свои кодировки, которые тоже нужно поменять.
Для всех таблиц, колонок, файлов, сервера и вообще всего, что связано с сайтом, должна быть одна кодировка.
Проблема может не решиться, если все дело в кодировке подключения к базе данных. Что делать:
- Подключитесь к серверу с правами mysql root пользователя:mysql -u root -p
- Выберите нужную базу:USE имя_базы;
- Выполните запрос:SET NAMES ‘utf8’;
Если вы хотите указать Windows-1251, то пишите не «utf-8», а «cp1251» — обозначение для кодировки Windows-1251 у MySQL.
Чтобы установить UTF-8 по умолчанию, откройте на сервере my.cnf и добавьте следующее:
Вы когда-нибудь сталкивались с проблемами кодировки на сайте?
Конфликт кодировок
Полностью локализованная консоль в идеале должна поддерживать все мыслимые и немыслимые кодировки приложений, включая свои собственные команды и команды Windows, меняя «на лету» кодовые страницы потоков ввода и вывода. Задача нетривиальная, а иногда и невозможная — кодовые страницы DOS (CP437, CP866) плохо совмещаются с кодовыми страницами Windows и Unicode.
История кодировок здесь: О кодировках и кодовых страницах / Хабр (habr.com)
Исторически кодовой страницей Windows является CP1251 (Windows-1251, ANSI, Windows-Cyr), уверенно вытесняемая 8-битной кодировкой Юникода CP65001 (UTF-8, Unicode Transformation Format), в которой выполняется большинство современных приложений, особенно кроссплатформенных. Между тем, в целях совместимости с устаревшими файловыми системами, именно в консоли Windows сохраняет базовые кодировки DOS — CP437 (DOSLatinUS, OEM) и русифицированную CP866 (AltDOS, OEM).
Поскольку в консоли постоянно происходит передача управления от приложений к собственно командному процессору и обратно, регулярно возникает «конфликт кодировок», наглядно иллюстрируемый таблица 1 и 2, сформированных следующим образом:
Были запущены три консоли — CMD, PS и WPS. В каждой консоли менялась кодовая страница с помощью команды CHCP, выполнялась команда Echo c двуязычной строкой в качестве параметра (табл. 1), а затем в консоли запускалось тестовое приложение, исходные файлы которого были созданы в кодировке UTF-8 (CP65001): первая строка формируется и направляется в поток главным модулем, вторая вызывается им же, формируется в подключаемой библиотеке классов и направляется в поток опять главным модулем, третья строка полностью формируется и направляется в поток подключаемой библиотекой.
Командную часть задания все консоли локализовали практически без сбоев во всех кодировках, за исключением: в WPS неверно отображена русскоязычная часть команды во всех кодировках.
Табл. 1. Результат выполнения команды консоли Echo ffffff фффффф
Вывод тестового приложения локализован лишь в 50% испытаний, как показано в табл.2.
Табл. 2. Результат запуска приложения LoggingConsole.Test
По умолчанию Windows устанавливает для консоли кодовые страницы DOS. Чаще всего CP437, иногда CP866. Актуальные версии командной строки cmd.exe способны локализовать приложения на основе русифицированной кодовой страницы 866, но не 437, отсюда и изначальный конфликт кодировок консоли и приложения. Поэтому
Как сменить кодировку в консоли windows?
Файл должен выводиться в utf-8, а в консоли — 866, в итоге в браузере отображаются ромбы.
После команды chcp 65001 ничего не поменялось.
Но у меня в CodePage таких файлов нет. Есть типы REG.SZ по умолчанию и 4 файла с номерами 932 936 949 950
Вариант постоянно изменять в консоли chcp не подходит, но и не работает. Lucida console подключен в консоли. Cygwin64 Terminal и Gitbash не запускает python server
Какие-то ещё есть варианты?
generate.py
horoscope.py
При запуске кода (python generate_all.py из командной строки или Ctrl B в саблайме) в этой же папке генерируется файл index.html, и, если поднять сервер в этой же директории (python -m http.server) из консоли win, то в браузере ромбы.
Спасшая статья:
Приложение cmd.exe – это командная строка или программная оболочка с текстовым интерфейсом (во загнул ).
Запустить командную строку можно следующим способом: Пуск → Выполнить → вводим в поле команду – cmd и жмем ОК. В итоге откроется рабочее окно программы – c:WINDOWSsystem32cmd.exe. ( рис.1)
Если Вы занялись проблемой кодировки шрифтов в cmd.exe , то как запускать командную строку наверняка уже знаете
Перейдем собственно к проблеме: иногда вместо русских букв при выполнении команд выходит набор непонятных символов ( рис.2).
Первым делом нужно зайти в свойства окна – правой кнопкой щелкнуть по верхней части окна → Свойства → выйдет окно рис.3, здесь в поле Шрифтвыбираем Lucida Console и жмем ОК.
Теперь Вы получили нормальный текст на русском языке. Так же можно поменять текущую кодировку шрифта, для этого используется команда chcp. Набираем эту команду и жмем Enter, в результате получим текущую кодировку для командной строки – рис.4.
Для изменения кодировки так же применим chcp в следующем формате:
Где – это цифровой параметр нужного шрифта, например,
1251 – Windows (кириллица);
Выбирайте на любой вкус. Т.о. что бы изменить кодировку на UTF-8 нужно выполнить команду chcp 65001.
almixРазработчик Loco, автор статей по веб-разработке на Yii, CodeIgniter, MODx и прочих инструментах. Создатель Team Sense.
Источник
Неправильная кодировка HTML страниц
Создадим тестовый файлик:
sudo gedit /var/www/html/encoding.html
Скопируем в него следующий HTML код, в котором отсутствует указание кодировки и посмотрим, какие проблемы могут с ним возникнуть и как их решить:
<html>
<head>
<title>Проверка кодировки</title>
</head>
<body>
<h1>Тестовый файл для проверки кодировки</h1>
</body>
</html>
Откроем этот файл в браузере http://localhost/encoding.html
Как можно видеть, кодировка браузером определена неправильно:

Имеется несколько способов исправить эту ситуацию. Начнём с самого простого – явно указать кодировку для веб-страницы. Это делается метатегом, который должен быть расположен внутри тэга head:
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
Добавим эту строку к нашему тестовому файлику, чтобы получилось так:
<html>
<head>
<title>Проверка кодировки</title>
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
</head>
<body>
<h1>Тестовый файл для проверки кодировки</h1>
</body>
</html>
Как мы можем убедиться на следующем скриншоте, проблема решена:

Если кодировка вашего файла отличается от UTF-8, то вместо неё поставьте windows-1251 или ту, которая соответствует кодировке веб-страницы. Чтобы научиться определять кодировку файлов, посмотрите эту инструкцию.
Это был самый простой способ исправления проблемы с кодировкой – без изменения настроек сервера.
Вернём наш тестовый файл в исходное состояние и продолжим изучение способов указания кодировки.
Если файлы .htaccess включены настройками Apache, то эти файлы можно использовать чтобы указывать кодировку отправляемых веб-сервером страниц. Чтобы включить поддержку файлов .htaccess в конфигурационном файле Apache ( /etc/apache2/apache2.conf ) найдите группу строк
<Directory /var/www/> Options Indexes FollowSymLinks AllowOverride None Require all granted </Directory>
И в ней замените
AllowOverride None
на
AllowOverride All
После этого сервер нужно перезапустить.
sudo systemctl restart apache2.service
Файл .htaccess должен быть размещён в той же директории, что и сайт. Мой сайт размещён в корневой директории веб-сервера. Если у вас также, то теперь в папке /var/www/html/ создайте файл .htaccess и добавьте в него директиву AddDefaultCharset после которой укажите желаемую кодировку. Примеры
AddDefaultCharset UTF-8
ИЛИ
AddDefaultCharset windows-1251
Можно указать кодировку, которая будет применена только к файлам определённого формата:
AddCharset utf-8 .atom .css .js .json .rss .vtt .xml
Набор файлов может быть любым, например:
AddCharset utf-8 .html .css .php .txt .js
Следующий вариант является альтернативным и также позволяет устанавливать кодировку для файлов определённого типа, для него нужно, чтобы был включён mod_headers:
<Files ~ "\.html?$">
Header set Content-Type "text/html; charset=utf-8"
</Files>
Ещё один вариант, который также можно использовать в файле .htaccess для установки кодировки UTF-8:
IndexOptions +Charset=utf-8
Если сайт на PHP, то дополнительно может понадобиться продублировать кодировку с php_value default_charset:
AddDefaultCharset windows-1251 php_value default_charset "cp1251"
Можно вместо создания файла .htaccess установить кодировку в конфигурационном файле веб-сервера. Для Apache CentOS/Fedora это файл httpd.conf, а на Debian/Ubuntu это файл apache2.conf. Добавьте следующую строку для установки кодировки и перезапустите веб-сервер, чтобы изменения вступили в силу:
AddDefaultCharset UTF-8
Кодировки стандарта UNICODE
Юникод (англ. Unicode) — стандарт кодирования символов, позволяющий представить знаки почти всех письменностей мира, и специальных символов. Представляемые в юникоде символы кодируются целыми числами без знака. Юникод имеет несколько форм представления символов в компьютере: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). (Англ. Unicode transformation format — UTF).UTF-8 — это в настоящее время распространённая кодировка, которая нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий из символов Unicode с номерами меньше 128 (область с кодами от U+0000 до U+007F), содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F.
Кодировка UTF-8 является универсальной и имеет внушительный резерв на будущее. Это делает ее наиболее удобной кодировкой для использования в интернете.
HTML Символы
Кодирование URL
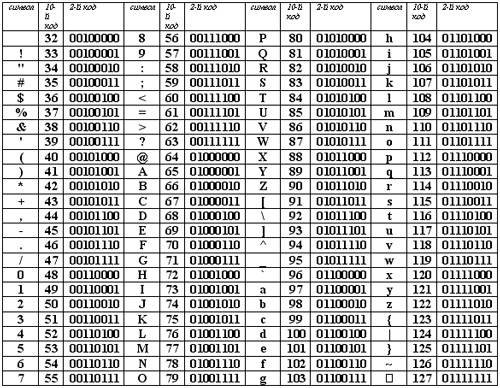
Таблица кодов символов Windows-1251
Windows-1251 — набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Данная кодировка пользуется довольно большой популярностью в восточно-европейских странах.
Windows-1251 выгодно отличается от других 8-битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в традиционной русской типографике для обычного текста (отсутствует только знак ударения). Кириллические символы идут в алфавитном порядке.
Windows-1251 также содержит все символы для близких к русскому языку языков: белорусского, украинского, сербского, македонского и болгарского.
На практике этого оказалось достаточно, чтобы кодировка Windows-1251 закрепилась в интернете вплоть до распространения UTF-8.
| 000 | 00 | NOP | 128 | 80 | Ђ |
| 001 | 01 | SOH | 129 | 81 | Ѓ |
| 002 | 02 | STX | 130 | 82 | ‚ |
| 003 | 03 | ETX | 131 | 83 | ѓ |
| 004 | 04 | EOT | 132 | 84 | „ |
| 005 | 05 | ENQ | 133 | 85 | … |
| 006 | 06 | ACK | 134 | 86 | † |
| 007 | 07 | BEL | 135 | 87 | ‡ |
| 008 | 08 | BS | 136 | 88 | € |
| 009 | 09 | TAB | 137 | 89 | ‰ |
| 010 | 0A | LF | 138 | 8A | Љ |
| 011 | 0B | VT | 139 | 8B | ‹ |
| 012 | 0C | FF | 140 | 8C | Њ |
| 013 | 0D | CR | 141 | 8D | Ќ |
| 014 | 0E | SO | 142 | 8E | Ћ |
| 015 | 0F | SI | 143 | 8F | Џ |
| 016 | 10 | DLE | 144 | 90 | ђ |
| 017 | 11 | DC1 | 145 | 91 | ‘ |
| 018 | 12 | DC2 | 146 | 92 | ’ |
| 019 | 13 | DC3 | 147 | 93 | “ |
| 020 | 14 | DC4 | 148 | 94 | ” |
| 021 | 15 | NAK | 149 | 95 | • |
| 022 | 16 | SYN | 150 | 96 | – |
| 023 | 17 | ETB | 151 | 97 | — |
| 024 | 18 | CAN | 152 | 98 | |
| 025 | 19 | EM | 153 | 99 | |
| 026 | 1A | SUB | 154 | 9A | љ |
| 027 | 1B | ESC | 155 | 9B | › |
| 028 | 1C | FS | 156 | 9C | њ |
| 029 | 1D | GS | 157 | 9D | ќ |
| 030 | 1E | RS | 158 | 9E | ћ |
| 031 | 1F | US | 159 | 9F | џ |
| 032 | 20 | SP | 160 | A0 | |
| 033 | 21 | ! | 161 | A1 | Ў |
| 034 | 22 | “ | 162 | A2 | ў |
| 035 | 23 | # | 163 | A3 | Ћ |
| 036 | 24 | $ | 164 | A4 | ¤ |
| 037 | 25 | % | 165 | A5 | Ґ |
| 038 | 26 | & | 166 | A6 | ¦ |
| 039 | 27 | ‘ | 167 | A7 | § |
| 040 | 28 | ( | 168 | A8 | Ё |
| 041 | 29 | ) | 169 | A9 | |
| 042 | 2A | * | 170 | AA | Є |
| 043 | 2B | + | 171 | AB | |
| 044 | 2C | , | 172 | AC | ¬ |
| 045 | 2D | – | 173 | AD | |
| 046 | 2E | . | 174 | AE | |
| 047 | 2F | 175 | AF | Ї | |
| 048 | 30 | 176 | B0 | ° | |
| 049 | 31 | 1 | 177 | B1 | ± |
| 050 | 32 | 2 | 178 | B2 | І |
| 051 | 33 | 3 | 179 | B3 | і |
| 052 | 34 | 4 | 180 | B4 | ґ |
| 053 | 35 | 5 | 181 | B5 | µ |
| 054 | 36 | 6 | 182 | B6 | ¶ |
| 055 | 37 | 7 | 183 | B7 | · |
| 056 | 38 | 8 | 184 | B8 | ё |
| 057 | 39 | 9 | 185 | B9 | № |
| 058 | 3A | 186 | BA | є | |
| 059 | 3B | ; | 187 | BB | |
| 060 | 3C | 190 | BE | ѕ | |
| 063 | 3F | ? | 191 | BF | ї |
| 064 | 40 | @ | 192 | C0 | А |
| 065 | 41 | A | 193 | C1 | Б |
| 066 | 42 | B | 194 | C2 | В |
| 067 | 43 | C | 195 | C3 | Г |
| 068 | 44 | D | 196 | C4 | Д |
| 069 | 45 | E | 197 | C5 | Е |
| 070 | 46 | F | 198 | C6 | Ж |
| 071 | 47 | G | 199 | C7 | З |
| 072 | 48 | H | 200 | C8 | И |
| 073 | 49 | I | 201 | C9 | Й |
| 074 | 4A | J | 202 | CA | К |
| 075 | 4B | K | 203 | CB | Л |
| 076 | 4C | L | 204 | CC | М |
| 077 | 4D | M | 205 | CD | Н |
| 078 | 4E | N | 206 | CE | О |
| 079 | 4F | O | 207 | CF | П |
| 080 | 50 | P | 208 | D0 | Р |
| 081 | 51 | Q | 209 | D1 | С |
| 082 | 52 | R | 210 | D2 | Т |
| 083 | 53 | S | 211 | D3 | У |
| 084 | 54 | T | 212 | D4 | Ф |
| 085 | 55 | U | 213 | D5 | Х |
| 086 | 56 | V | 214 | D6 | Ц |
| 087 | 57 | W | 215 | D7 | Ч |
| 088 | 58 | X | 216 | D8 | Ш |
| 089 | 59 | Y | 217 | D9 | Щ |
| 090 | 5A | Z | 218 | DA | Ъ |
| 091 | 5B | 219 | DB | Ы | |
| 092 | 5C | 220 | DC | Ь | |
| 093 | 5D | 221 | DD | Э | |
| 094 | 5E | ^ | 222 | DE | Ю |
| 095 | 5F | _ | 223 | DF | Я |
| 096 | 60 | ` | 224 | E0 | а |
| 097 | 61 | a | 225 | E1 | б |
| 098 | 62 | b | 226 | E2 | в |
| 099 | 63 | c | 227 | E3 | г |
| 100 | 64 | d | 228 | E4 | д |
| 101 | 65 | e | 229 | E5 | е |
| 102 | 66 | f | 230 | E6 | ж |
| 103 | 67 | g | 231 | E7 | з |
| 104 | 68 | h | 232 | E8 | и |
| 105 | 69 | i | 233 | E9 | й |
| 106 | 6A | j | 234 | EA | к |
| 107 | 6B | k | 235 | EB | л |
| 108 | 6C | l | 236 | EC | м |
| 109 | 6D | m | 237 | ED | н |
| 110 | 6E | n | 238 | EE | о |
| 111 | 6F | o | 239 | EF | п |
| 112 | 70 | p | 240 | F0 | р |
| 113 | 71 | q | 241 | F1 | с |
| 114 | 72 | r | 242 | F2 | т |
| 115 | 73 | s | 243 | F3 | у |
| 116 | 74 | t | 244 | F4 | ф |
| 117 | 75 | u | 245 | F5 | х |
| 118 | 76 | v | 246 | F6 | ц |
| 119 | 77 | w | 247 | F7 | ч |
| 120 | 78 | x | 248 | F8 | ш |
| 121 | 79 | y | 249 | F9 | щ |
| 122 | 7A | z | 250 | FA | ъ |
| 123 | 7B | { | 251 | FB | ы |
| 124 | 7C | | | 252 | FC | ь |
| 125 | 7D | } | 253 | FD | э |
| 126 | 7E | ~ | 254 | FE | ю |
| 127 | 7F | DEL | 255 | FF | я |
Описание специальных (управляющих) символов
Первоначально управляющие символы таблицы ASCII (диапазон 00-31, плюс 127) были разработаны для того, чтобы управлять устройствами аппаратных средств, таких как телетайп, ввод данных на перфоленту и др.Управляющие символы (кроме горизонтальной табуляции, перевода строки и возврата каретки) не используются в HTML-документах.
КодОписание
NUL, 00
Null, пустой
SOH, 01
Start Of Heading, начало заголовка
STX, 02
Start of TeXt, начало текста
ETX, 03
End of TeXt, конец текста
EOT, 04
End of Transmission, конец передачи
ENQ, 05
Enquire. Прошу подтверждения
ACK, 06
Acknowledgement. Подтверждаю
BEL, 07
Bell, звонок
BS, 08
Backspace, возврат на один символ назад
TAB, 09
Tab, горизонтальная табуляция
LF, 0A
Line Feed, перевод строкиСейчас в большинстве языков программирования обозначается как
VT, 0B
Vertical Tab, вертикальная табуляция
FF, 0C
Form Feed, прогон страницы, новая страница
CR, 0D
Carriage Return, возврат кареткиСейчас в большинстве языков программирования обозначается как
SO, 0E
Shift Out, изменить цвет красящей ленты в печатающем устройстве
SI, 0F
Shift In, вернуть цвет красящей ленты в печатающем устройстве обратно
DLE, 10
Data Link Escape, переключение канала на передачу данных
DC1, 11 DC2, 12DC3, 13DC4, 14
Device Control, символы управления устройствами
NAK, 15
Negative Acknowledgment, не подтверждаю
SYN, 16
Synchronization. Символ синхронизации
ETB, 17
End of Text Block, конец текстового блока
CAN, 18
Cancel, отмена переданного ранее
EM, 19
End of Medium, конец носителя данных
SUB, 1A
Substitute, подставить. Ставится на месте символа, значение которого было потеряно или испорчено при передаче
ESC, 1B
Escape Управляющая последовательность
FS, 1C
File Separator, разделитель файлов
GS, 1D
Group Separator, разделитель групп
RS, 1E
Record Separator, разделитель записей
US, 1F
Unit Separator, разделитель юнитов
DEL, 7F
Delete, стереть последний символ.
Как исправить иероглифы Windows 10 путем изменения кодовых страниц
Кодовые страницы представляют собой таблицы, в которых определенным байтам сопоставляются определенные символы, а отображение кириллицы в виде иероглифов в Windows 10 связано обычно с тем, что по умолчанию задана не та кодовая страница и это можно исправить несколькими способами, которые могут быть полезны, когда требуется не изменять язык системы в параметрах.
С помощью редактора реестра
Первый способ — использовать редактор реестра. На мой взгляд, это самый щадящий для системы метод, тем не менее, рекомендую создать точку восстановления прежде чем начинать. Совет про точки восстановления относится и ко всем последующим способам в этом руководстве.
Обычно, это исправляет проблему с отображением русских букв. Вариация способа с помощью редактора реестра (но менее предпочтительная) — посмотреть на текущее значение параметра ACP (обычно — 1252 для изначально англоязычных систем), затем в том же разделе реестра найти параметр с именем 1252 и изменить его значение с c_1252.nls на c_1251.nls.
Путем подмена файла кодовой страницы на c_1251.nls
Второй, не рекомендуемый мной способ, но иногда выбираемый теми, кто считает, что правка реестра — это слишком сложно или опасно: подмена файла кодовой страницы в C:\ Windows\ System32 (предполагается, что у вас установлена западно-европейская кодовая страница — 1252, обычно это так. Посмотреть текущую кодовую страницу можно в параметре ACP в реестре, как было описано в предыдущем способе).
После перезагрузки Windows 10 кириллица должна будет отображаться не в виде иероглифов, а как обычные русские буквы.
Таблицы кодировок [ править ]
На заре компьютерной эры на каждый символ было отведено по пять бит. Это было связано с малым количеством оперативной памяти на компьютерах тех лет. В эти 32 символа входили только управляющие символы и строчные буквы английского алфавита.
С ростом производительности компьютеров стали появляться таблицы кодировок с большим количеством символов. Первой семибитной кодировкой стала ASCII7. В нее уже вошли прописные буквы английского алфавита, арабские цифры, знаки препинания. Затем на ее базе была разработана ASCII8, в которым уже стало возможным хранение 256 символов: 128 основных и еще столько же расширенных. Первая часть таблицы осталась без изменений, а вторая может иметь различные варианты (каждый имеет свой номер). Эта часть таблицы стала заполняться символами национальных алфавитов.
Но для многих языков (например, арабского, японского, китайского) 256 символов недостаточно, поэтому развитие кодировок продолжалось, что привело к появлению UNICODE.
Казахский вариант
Измененная версия Windows-1251 была стандартизирована в Казахстане как казахстанский стандарт STRK1048 и известна под этикеткой . Он отличается в строках, показанных ниже:
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _A | _B | _C | _D | _E | _F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8_ 128 | Ђ 0402 | Ѓ 0403 | ‚ 201A | ѓ 0453 | „ 201E | … 2026 г. | † 2020 г. | ‡ 2021 г. | € 20AC | ‰ 2030 г. | Љ 0409 | ‹ 2039 | Њ 040A | Қ 049A | Һ 04BA | Џ 040F |
| 9_ 144 | ђ 0452 | ‘ 2018 | ‘ 2019 | 201C | ” 201D | • 2022 г. | — 2013 г. | — 2014 г. | 2122 | љ 0459 | › 203A | њ 045A | қ 049B | һ 04BB | џ 045F | |
| A_ 160 | NBSP 00A0 | Ұ 04B0 | ұ 04B1 | Ә 04D8 | ¤ 00A4 | Ө 04E8 | ¦ 00A6 | § 00A7 | Ё 0401 | 00A9 | Ғ 0492 | 00AB | ¬ 00AC | SHY 00AD | 00AE | Ү 04AE |
| B_ 176 | ° 00B0 | ± 00B1 | І 0406 | і 0456 | ө 04E9 | µ 00B5 | ¶ 00B6 | · 00B7 | ё 0451 | № 2116 | ғ 0493 | 00BB | ә 04D9 | Ң 04A2 | ң 04A3 | ү 04AF |
Faster — многофункциональный ускоритель работы программиста 1С и других языков программирования Промо
Программа Faster 9.4 позволяет ускорить процесс работы программиста
(работает в любом текстовом редакторе).
Подсказка при вводе текста на основе ранее введенного текста и настроенных шаблонов.
Программа Faster позволяет делится кодом с другими программистами в два клика или передать ссылку через QR Код.
Исправление введенных фраз двойным Shift (с помощью speller.yandex). Переводчик текста. Переворачивает текст случайно набранный на другой раскладке.
Полезная утилита для тех, кто печатает много однотипного текста, кодирует в среде Windows на разных языках программирования.
Через некоторое время работы с программой у вас соберется своя база часто используемых словосочетаний и кусков кода.
Настройка любых шорткатов под себя с помощью скриптов.
Никаких установок и лицензий, все бесплатно.
1 стартмани
Особенности
Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста (отсутствует только значок ударения); Она также содержит все символы для других славянских языков: украинского, белорусского, сербского, македонского и болгарского.
Windows-1251 имеет два недостатка:
- строчная буква «я» имеет код 0xFF (255 в десятичной системе). Она является «виновницей» ряда неожиданных проблем в программах без поддержки чистого 8-го бита, а также (гораздо более частый случай) использующих этот код как служебный (в CP437 он обозначает «неразрывный пробел», в Windows-1252 — ÿ, оба варианта практически не используются; число же -1, в дополнительном коде длиной 8 бит представляющееся числом 255, часто используется в программировании как специальное значение). Тот же недостаток имеет и KOI8-R, но в ней 0xFF есть заглавный твердый знак, который применяется редко (только при написании одними лишь заглавными буквами).
- отсутствуют символы псевдографики, имеющиеся в CP866 и KOI8 (хотя для самих Windows, для которых она предназначена, в них не было нужды, это делало несовместимость двух использовавшихся в них кодировок заметнее).
Также как недостаток может рассматриваться отдельное расположение буквы «ё», тогда как остальные символы расположены строго в алфавитном порядке. Это усложняет программы лексикографического упорядочения.
Синонимы: CP1251; ANSI (только в русскоязычной ОС Windows).
Немного теории
Любой документ на компьютере или в интернете, как я уже сказал, хранится в виде двоичного кода. К примеру, если вы используете кодировку ASCII, то буква «К» будет записана как 10001010, а windows 1251 под этим числом скрывается символ – Љ. В итоге, если браузер или программа обратится к другой таблице и считает вместо ASCII коды windows 1251, то читатель увидит совершенно непонятные ему символ.
Логичен вопрос, нафига было придумывать множество таблиц с кодами? Дело в том, что помимо русского алфавита существует еще и английский, немецкий, китайский. По некоторым подсчетам, существует около 200 000 символов. Хотя, я не очень доверяю этой статистике, вспоминая про японский.
Не забывайте, что для заглавной и строчной буквы нужно придумать свой код, есть запятые, тире и так далее.
Чем больше в таблице символов, тем длиннее код каждого из них, а значит и вес документа становится больше.
Представьте, если бы одна книга весила 4 Гб! Она бы очень долго загружалась, занимала все свободное место на компьютере. Решение о скачивании представлялось бы делом нелегким.
Если вспомнить о сайтах, то вообще страшно подумать, что бы произошло. Каждая страничка открывалась даже на скоростном оптоволокне по часу с лишним! Думаю, мобильные телефоны можно было бы смело выкидывать. Пользоваться ими на улице даже с 4G? Сомневаюсь.
По этим причинам каждый программист в свое время старался придумать свою таблицу символов. Чтобы было удобно для использования и вес сохранялся оптимальным.
Microsoft, к примеру, для русскоязычного сегмента создали windows-1251. В ней, конечно же, есть свои достоинства и недостатки. Как и у любого другого продукта.
Сейчас уже, лишь 2% всех страниц в интернете написано на 1251. Большинство веб-мастеров используют UTF-8. Почему так?
Пометка порядка байтов
Символ-пометка (BOM) — это сигнатура в Юникоде в первых нескольких байтах файла или текстового потока, указывающих, какая кодировка Юникода используется для данных. Дополнительные сведения см. в документации по метке порядка байтов .
в Windows PowerShell любая кодировка юникода, за исключением , всегда создает спецификацию. По умолчанию PowerShell Core имеет значение для всех текстовых выходных данных.
Для обеспечения оптимальной совместимости Избегайте использования спецификаций в файлах UTF-8. платформы unix и служебные программы unix-heritage, также используемые на платформах Windows, не поддерживают спецификации.
Аналогичным образом следует избегать кодирования. UTF-7 не является стандартной кодировкой Юникода и записывается без спецификации во всех версиях PowerShell.
создание сценариев PowerShell на платформе, похожем на Unix, или использовании кросс-платформенного редактора на Windows, например Visual Studio Code, приводит к созданию файла, закодированного с помощью . эти файлы прекрасно работают в PowerShell Core, но могут нарушить работу Windows PowerShell если файл содержит символы, отличные от Ascii.
Если в скриптах необходимо использовать символы, отличные от ASCII, сохраните их как UTF-8 с помощью BOM. без спецификации Windows PowerShell правильно интерпретирует скрипт как закодированный в устаревшей кодовой странице ANSI. И наоборот, файлы, имеющие СПЕЦИФИКАЦИю UTF-8, могут быть проблематичными для платформ, подобных Unix. Многие средства UNIX, такие как ,, и некоторые редакторы, например, не узнают, как обрабатывать спецификацию.
Базовая таблица кодировки ASCII
| 32 пробел | 48 0 | 64 @ | 80 P | 96 ` | 112 p |
| 33 ! | 49 1 | 65 A | 81 Q | 97 a | 113 q |
| 34 “ | 50 2 | 66 B | 82 R | 98 b | 114 r |
| 35 # | 51 3 | 67 C | 83 S | 99 c | 115 s |
| 36 $ | 52 4 | 68 D | 84 T | 100 d | 116 t |
| 37 % | 53 5 | 69 E | 85 U | 101 e | 117 u |
| 38 & | 54 6 | 70 F | 86 V | 102 f | 118 v |
| 39 ‘ | 55 7 | 71 G | 87 W | 103 g | 119 w |
| 40 ( | 56 8 | 72 H | 88 X | 104 h | 120 x |
| 41 ) | 57 9 | 73 I | 89 Y | 105 i | 121 y |
| 42 * | 58 : | 74 J | 90 Z | 106 j | 122 z |
| 43 + | 59 ; | 75 K | 91 [ | 107 k | 123 { |
| 44 , | 60 < | 76 L | 92 \ | 108 l | 124 | |
| 45 — | 61 = | 77 M | 93 ] | 109 m | 125 } |
| 46 . | 62 > | 78 N | 94 ^ | 110 n | 126 ~ |
| 47 / | 63 ? | 79 O | 95 _ | 111 o | 127 |
Символы с номерами от 128 до 255 представляют собой таблицу расширения и варьируются в зависимости от набора скриптов, представленных кодировкой символов. Набор символов таблицы расширения различается в зависимости от выбранной кодовой страницы:
Преобразование кодовой страницы
по мере того, как Windows работает в кодировке utf-16 ( ), может потребоваться преобразовать данные utf-8 в utf-16 (или наоборот) для взаимодействия с интерфейсами api Windows.
MultiByteToWideChar и WideCharToMultiByte позволяют выполнить преобразование между UTF-8 и UTF-16 ( ) (и другими кодовыми страницами). Это особенно полезно, когда устаревший API Win32 может понимать только . Эти функции позволяют преобразовать входные данные UTF-8 в для передачи в API-интерфейс, а затем преобразовать все результаты при необходимости.
При использовании этих функций с параметром , имеющим значение, используйте либо или , в противном случае — .
Примечание
соответствует только в том случае, если работает на Windows версии 1903 (май 2019) или выше, а свойство активекодепаже, описанное выше, имеет значение UTF-8. В противном случае она учитывает устаревшую системную кодовую страницу. Рекомендуется использовать явно.