Кодирование от алкоголизма что это и как происходит
Содержание:
- Введение
- Где указать кодировку сайта
- Как установить UTF-8 кодировку в PHP
- Неправильная кодировка результатов из базы данных MySQL
- Что представляет собой кодировка и от чего она зависит?
- Изменение при открытии
- Добавление скрытых символов в текст
- Пример
- Смена кодировки прямо в браузере
- Почему кодирование подходит не всем?
- Перекодировка текста
- Немного теории
- Два метода, как поменять шифровку в Word
- Исправление отображения кириллицы с помощью настроек языка и региональных стандартов Windows 10
- Как исправить поврежденную кодировку символов (поврежденный текст) в Microsoft Word
- Изменение кодировки в программе «Notepad ++»
- Смена кодировки текста в Microsoft Word
- Базы банных
Введение
Я очень люблю программировать, я любитель и первый и последний раз заработал на программировании в далёком 1996 году. Но для автоматизации повседневных задач иногда что-то пишу. Примерно год назад открыл для себя golang. В качестве инструмента создания утилит golang оказался очень удобным. Итак.
Возникла потребность обработать большое количество (больше тысячи, так и вижу улыбки профи) архивных файлов со специальной геофизической информацией. Формат файлов текстовый, простой. Если вдруг интересно то это LAS формат.
LAS файл содержит заголовок и данные.
Данные практически CSV, только разделитель табуляция или пробелы.
А заголовок содержит описание данных и вот в нём обычно содержится русский текст. Это может быть название месторождение, название исследований записанных в файл и пр.
Файлы эти созданы в разное время и в разных программах, доходит до того что в одном файле часть в кодировке CP1251 а часть в CP866. Файлы эти мне нужно обработать, а значит понять. Вот и потребовалось определять автоматически кодировку файла.
В итоге изобрёл велосипед на golang и соответственно родилась маленькая библиотечка с возможностью детектировать кодовую страницу.
Про кодировки. Не так давно на хабре была хорошая статья про кодировки Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор Если хочется понять что такое “кракозябры” или “кости” то стоит прочитать.
В начале я накидал своё решение. Потом пытался найти готовое работающее решение на golang, но не вышло. Нашлось два решения, но оба не работают.
- Первое “из коробки”— golang.org/x/net/html/charset функция DetermineEncoding()
- Второе библиотека — saintfish/chardet на github
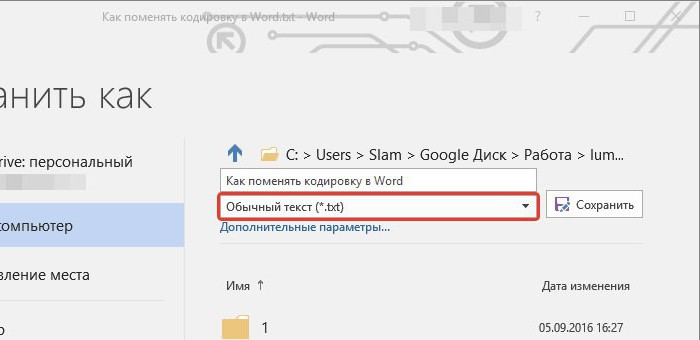
Обе уверенно ошибаются на некоторых кодировках. Стандартная та вообще почти ничего определить не может по текстовым файлам, оно и понятно, её для html страниц делали.
При поиске часто натыкался на готовые утилиты из мира linux — enca. Нашёл её версию скомпилированную для WIN32, версия 1.12. Её я тоже рассмотрю, там есть забавности. Я прошу сразу прощения за своё полное незнание linux, а значит возможно есть ещё решения которые тоже можно попытаться прикрутить к golang коду, я больше искать не стал.
Где указать кодировку сайта
Если проблема возникла на вашем сайте, способ исправления зависит от вида сайта. Для одностраничника достаточно указать кодировку в мета-теге страницы, а для большого сайта есть разные варианты:
- кодировка в мета-теге;
- кодировка в .htaccess;
- кодировка документа;
- кодировка в базе данных MySQL.
Кодировка в мета-теге
Добавьте указание кодировки в head файла шаблона сайта.
При создании документа HTML укажите тег meta в начале в блоке head. Некоторые браузеры могут не распознать указание кодировки, если оно будет ниже.
Мета-тег может выглядеть так:
или так:
В HTML5 они эквивалентны.
Тег кодировки в HTML
В темах WordPress обычно тег «charset» с кодировкой указан по умолчанию, но лучше проверить.
Кодировка в файле httpd.conf
Инструкции для сервера находятся в файле httpd.conf, обычно его можно найти на пути «/usr/local/apache/conf/».
Если вам нужно сменить кодировку Windows-1251 на UTF-8, замените строчку «AddDefaultCharset windows-1251» на «AddDefaultCharset utf-8».
Убедитесь, что сервер не передает HTTP-заголовки с конфликтующими кодировками.
Кодировка в .htaccess
Добавьте кодировку в файл .htaccess:
- Откройте панель управления хостингом.
- Перейдите в корневую папку сайта.
- В файле .htaccess добавьте в самое начало код:
- для указания кодировки UTF-8 — AddDefaultCharset UTF-8;
- для указания кодировки Windows-1251 — AddDefaultCharset WINDOWS-1251.
- Перейдите на сайт и очистите кэш браузера.
Кодировка документа
Готовые файлы HTML важно сохранять в нужной кодировке сайта. Узнать текущую кодировку файла можно через Notepad++: откройте файл и зайдите в «Encoding»
Меняется она там же: чтобы сменить кодировку на UTF-8, выберите «Convert to UTF-8 without BOOM». Нужно выбрать «без BOOM», чтобы не было пустых символов.
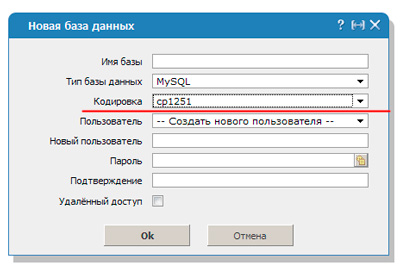
Кодировка Базы данных
Выбирайте нужную кодировку сразу при создании базы данных. Распространенный вариант — «UTF-8 general ci».
Где менять кодировку у БД:
- Кликните по названию нужной базы в утилите управления БД phpMyAdmin и откройте ее.
- Кликните на раздел «Операции»:
- Введите нужную кодировку для базы данных MySQL:
- Перейдите на сайт и очистите кэш.
С новой БД проще, но если вы меняете кодировку у существующей базы, то у созданных таблиц и колонок заданы свои кодировки, которые тоже нужно поменять.
Для всех таблиц, колонок, файлов, сервера и вообще всего, что связано с сайтом, должна быть одна кодировка.
Проблема может не решиться, если все дело в кодировке подключения к базе данных. Что делать:
- Подключитесь к серверу с правами mysql root пользователя:mysql -u root -p
- Выберите нужную базу:USE имя_базы;
- Выполните запрос:SET NAMES ‘utf8’;
Если вы хотите указать Windows-1251, то пишите не «utf-8», а «cp1251» — обозначение для кодировки Windows-1251 у MySQL.
Чтобы установить UTF-8 по умолчанию, откройте на сервере my.cnf и добавьте следующее:
Вы когда-нибудь сталкивались с проблемами кодировки на сайте?
Как установить UTF-8 кодировку в PHP
В PHP скрипте для установки кодировки используется header, например:
header('Content-Type: charset=utf-8');
Обычно вместе с кодировкой также указывают тип содержимого (в примере вариант для HTML страницы):
header('Content-Type: text/html; charset=utf-8');
Ещё один вариант для RSS ленты:
header('Content-type: text/xml; charset=utf-8');
Помните, что функция header должна быть вызвана перед любым выводом в браузер. В противном случае (если вывод в браузер уже был сделан), то уже были отправлены и заголовки. Очевидно, что в этом случае их уже невозможно поменять. Если в браузер было выведено сообщение об ошибке, то заголовки также уже были отправлены и использование header вызовет ошибку. Для проверки, были ли уже отправлены заголовки, используйте headers_sent.
Описанный способ работает только когда PHP скрипт полностью генерирует содержимое страницы. Статические страницы (такие как html) вы должны сохранять в кодировке utf-8
Большинство веб серверов обратят внимание на кодировку файла и добавят соответствующий заголовок. На самом деле, сохранение PHP файла в кодировке utf-8 приведёт к такому же результату.
Неправильная кодировка результатов из базы данных MySQL
Если ваш сайт состоит из статической части (шаблон) и динамической, которая формируется из данных, получаемых из базы данных, то может возникнуть ситуация, когда часть сайта имеет правильную кодировку, а другая часть сайта имеет неправильную. В этом случае бесполезно менять настройки веб-сервера – поскольку всё равно часть страницы будет иметь неправильную кодировку.
Нужно начать с определения кодировки ваших таблиц. Можно посмотреть в phpMyAdmin:

Обратите внимание на столбец «Сравнение», запись «utf8_unicode_ci» означает, что используется кодировка UTF-8.
Можно подключиться к СУБД MySQL и проверить кодировку таблиц без phpMyAdmin. Для этого:
mysql -u root -p
Если вы забыли имя базы данных, то выполните команду:
SHOW DATABASES;
Предположим, я хочу посмотреть кодировку для таблиц в базе данных information_schema
USE information_schema;
Если вы забыли имя таблиц, выполните:
SHOW TABLES;
Далее выполните команду, в которой имя_таблицы замените на настоящее имя таблицы:
SHOW FULL COLUMNS FROM имя_таблицы;
Например:
SHOW FULL COLUMNS FROM GLOBAL_STATUS;
Вы увидите примерно следующее:

Смотрите столбец Collation. В моём случае там utf8_general_ci, это, как и utf8_unicode_ci, кодировка UTF-8. Кстати, если вы не знаете в чём разница между кодировками utf8_general_ci, utf8_unicode_ci, utf8mb4_general_ci, utf8mb4_unicode_ci, а также какую кодировку выбрать для базы данных MySQL, то посмотрите эту статью.
Теперь, когда мы узнали кодировку (в моём случае это UTF-8), то при каждом подключении к СУБД MySQL нужно выполнять последовательно запросы:
SET NAMES UTF8 SET CHARACTER SET UTF8 SET character_set_client = UTF8 SET character_set_connection = UTF8 SET character_set_results = UTF8
В PHP это можно сделать примерно так:
$this->mysqli = new mysqli($server, $username, $password, $basename);
if ($this->mysqli->connect_error) {
$this->errorHandler_c->logError(1, 'Connect Error (' . $this->mysqli->connect_errno . ') ' . $this->mysqli->connect_error, $_SERVER );
}
$this->mysqli->query("SET NAMES UTF8");
$this->mysqli->query("SET CHARACTER SET UTF8");
$this->mysqli->query("SET character_set_client = UTF8");
$this->mysqli->query("SET character_set_connection = UTF8");
$this->mysqli->query("SET character_set_results = UTF8");
Обратите внимание, что UTF8 вам нужно заменить на ту кодировку, которая используется для ваших таблиц.
Что представляет собой кодировка и от чего она зависит?
Для каждого региона кодировка может в значительной степени разниться. Для понимания кодировки необходимо знать то, что информация в текстовом документе сохраняется в виде некоторых числовых значений. Персональный компьютер самостоятельно преобразует числа в текст, используя при этом алгоритм отдельно взятой кодировки. Для стран СНГ используется кодировка файлов с названием «Кириллица», а для других регионов, таких как Западная Европа, применяется «Западноевропейская (Windows)». Если текстовый документ был сохранен в кодировке кириллицы, а открыт с использованием западноевропейского формата, то символы будут отображаться совершенно неправильно, представляя собой бессмысленный набор знаков.
При открытии документа, сохраненного одним типом кодировки, в другом формате кодировки невозможно будет прочитать
Во избежание недоразумений и облегчения работы разработчики внедрили специальную единую кодировку для всех алфавитов – «Юникод». Этот общепринятый стандарт кодировки содержит в себе практически все знаки большинства письменных языков нашей планеты. К тому же он преобладает в интернете, где так необходима подобная унификация для охвата большего количества пользователей и удовлетворения их потребностей.
Возможно вас заинтересует: Как работать в Word для чайников
Тип кодировок, которые используются, как стандартные для всех языков
«Word 2013» работает как раз на основе Юникода, что позволяет обмениваться текстовыми файлами без применения сторонних программ и исправления кодировок в настройках. Но нередко пользователи сталкиваются с ситуацией, когда при открытии вроде бы простого файла вместо текста отображаются только знаки. В таком случае программа «Word» неправильно определила существующую первоначальную кодировку текста.
Изменение при открытии
Теперь поговорим о том, как изменить кодировку в Word. Способ, который сейчас будет представлен, подразумевает проведение этого действия при открытии документа.
Итак, чтобы произвести все настройки, необходимо:
Открыть документ. Также можно открыть саму программу без него, это допустимо.
Нажать на кнопку «Файл».
Перейти в меню «Параметры». Данный пункт располагается в нижней части панели слева.
Перейти в раздел «Дополнительно».
В окне пролистать меню до группы «Общие», поставить отметку рядом с «Подтверждать преобразование формата файла при открытии».
Так мы сказали программе, что при открытии файлов хотим проводить с ними дополнительные настройки. Поэтому сейчас необходимо закрыть программу, запустить проблемный файл с неверным кодом.
В Word 2010 изменить кодировку можно точно так же, просто вместо меню «Файл» надо нажимать кнопку MS Office.
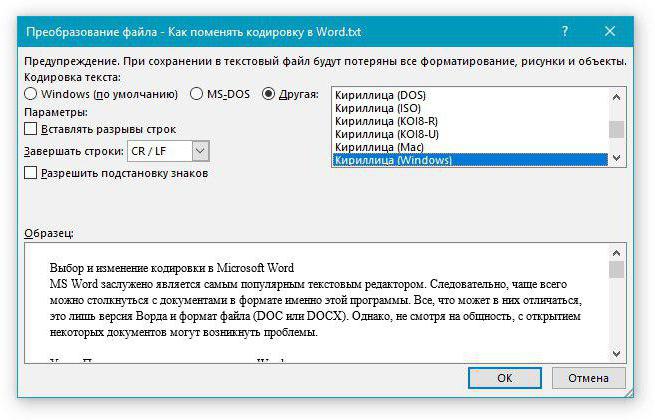
При открытии увидите окошко «Преобразование файла», необходимо в нем перейти в меню «Кодированный текст».
В верхней части окна поставьте пометку на пункте «Другая», чтобы список справа стал активен.
В списке надо выбрать кодировку файла. К слову, если вы не знаете, какая именно кодировка документа, то можно поочередно кликать каждую, просматривая результат в окошке «Образец». И когда текст станет читабелен, нажать «ОК».
Это был первый способ, как изменить кодировку текста в Word. А сейчас незамедлительно переходим ко второму.
Добавление скрытых символов в текст
Студенты придумали следующий оригинальный вариант увеличения уникальности. Они вставляют символы, написанные самым мелким шрифтом, или буквы, окрашенные в белый цвет. Такие знаки не видны в тексте, визуально не выделяются на общем фоне, а программы-анализаторы показывают высокую оригинальность.
Но разработчики систем антиплагиата знают эти способы и борются с ними. Тем более что при внесении этого контента в Word и нажатии кнопки «Очистить формат» большинство скрытых символов становятся видимыми.
В 2017 г. СМИ писали о студенте, который додумался создать в дипломной работе между 2 словами невидимый объект типа «Надпись» размером с 1 букву. Юноша вставил в него более 20 тыс. знаков контента, состоящего из 40 фрагментов одного и того же оригинального текста по 500 символов каждый.
Программа проверила материал и выдала отчет о высокой уникальности.
Эти знаки определялись как рисунок и не были видны в Word. Но программа-анализатор приняла их за необрабатываемый текст, прибавила все знаки к общему количеству и вывела приемлемый процент оригинальности.
Данный способ часто применяют студенты в своих работах.
Пример
Давайте посмотрим, маленький полностью рабочий пример. Будет использоваться шрифт Calligrapher, который Вы можете скачать на сайте — http://www.abstractfonts.com/ (сайт, предлагает большое количество бесплатных TrueType шрифтов). Ссылка для загрузки шрифта — http://www.abstractfonts.com/download/52. Первым шагом является генерация AFM-файла:ttf2pt1 -a calligra.ttf calligra
которая дает calligra.afm (и calligra.t1a, который можно удалить). Затем мы создаем файл определения:
require('font/makefont/makefont.php');
MakeFont('calligra.ttf','calligra.afm');
|
Вызов функции даст следующие сообщения:
Warning: character Euro is missing
Warning: character eth is missing
Font file compressed (calligra.z)
Font definition file generated (calligra.php)
Символ Euro отсутствует, так как слишком старый. Другие символы также отсутствуют, однако они нам не понадобятся.
Теперь можно скопировать два файла в директорию и написать сценарий:
require('fpdf.php');
$pdf=new FPDF();
$pdf->AddFont('Calligrapher','','calligra.php');
$pdf->AddPage();
$pdf->SetFont('Calligrapher','',35);
$pdf->Cell(,10,'Enjoy new fonts with FPDF!');
$pdf->Output();
|
Вот что должно получиться в итоге:

Смена кодировки прямо в браузере
В любом браузере есть специальная опция для перекодировки отдельной страницы. Так, в Гугл Хром нужно зайти в меню «Инструменты» и указать необходимую кодировку. Стандартными в рунете считается CP1251 (иногда с приставкой «Windows», «Microsoft») и UTF8. Последняя наиболее распространенная, она применяется на сайтах по умолчанию. В Опере, Мозилле и других браузерах также присутствует подобная функция. Обычно найти опцию несложно. Приводить подробные инструкции для каждого браузера нет смысла, потому как в них довольно часто выпускаются обновления, и расположение функциональных значков может меняться. А в Гугл Хром интерфейс уже давно остается примерно одинаковым.
Возможность смены кодировки при помощи Word или других приложений – очень полезная функция. Благодаря ей, даже оказавшись в чужеродной среде (в документе с непонятыми письменами), вы быстро наладите взаимопонимание с текстом. Вот бы так было за границей: захотел блеснуть на иностранном языке – переключил что-то в голове – и уже оперируешь чужестранными словами.
Когда вы открываете текстовый файл в Microsoft Word или другой программе (например, на компьютере, язык операционной системы на котором отличается от того, на котором написан текст в файле), кодировка помогает программе определить, в каком виде нужно вывести текст на экран, чтобы его можно было прочитать.
Почему кодирование подходит не всем?
Методика кодирования подходит не всем алкоголиком. Алкогольная зависимость чаще всего развивается из-за психологических факторов. Когда больной употребляет этиловый спирт для снятия волнения, страха, подавленного настроения, с помощью кодирования его не вылечить. Очередной запой произойдёт через определённое время.
Кодирование не поможет тем пациентам, которые не заинтересованы в собственном излечении.
Они отрицают у себя алкогольную зависимость. Обычно такие пациенты проходят антиалкогольную терапию под воздействием родственников. Если у человека отсутствует мотивация и имеется поверхностный подход к лечебным действиям нарколога, то всё это негативным образом скажется на эффективности кодирования.
Кодирование от алкоголизма является агрессивным воздействием на физиологические процессы и психоэмоциональную сферу больного. Поэтому перед кодированием требуется прохождение медицинского обследования и обязательна консультация врача.
Перекодировка текста
К сожалению, в разных версиях Word необходимые действия для изменения кодировки различны, хотя и ведут к одинаковому результату. Рассмотрим подробнее необходимые шаги для разных версий в отдельности:
Word 2003
Для того, что бы сменить кодировку, зайдите в меню и выберите СЕРВИС, а затем ПАРАМЕТРЫ. После этого в разделе ЗАКЛАДКА –Общие подтверждаем преобразование при открытии. Теперь при каждом следующем открытии текстового файла, будет предоставлена возможность выбора системы кодирования;
Word 2010, 2007
Эти версии в плане изменения шрифтов ничем не отличаются. В главном меню через ФАЙЛ заходим в ПАРАМЕТРЫ. В новом, выпадающем, окне выбираем раздел ДОПОЛНИТЕЛЬНО и в самом низу окна у Вас будет возможность «разметить документ так, будто он создан … ». Вам будут представлена возможность и создавать, и читать документы в нужном формате.
Немного теории
Любой документ на компьютере или в интернете, как я уже сказал, хранится в виде двоичного кода. К примеру, если вы используете кодировку ASCII, то буква «К» будет записана как 10001010, а windows 1251 под этим числом скрывается символ – Љ. В итоге, если браузер или программа обратится к другой таблице и считает вместо ASCII коды windows 1251, то читатель увидит совершенно непонятные ему символ.
Логичен вопрос, нафига было придумывать множество таблиц с кодами? Дело в том, что помимо русского алфавита существует еще и английский, немецкий, китайский. По некоторым подсчетам, существует около 200 000 символов. Хотя, я не очень доверяю этой статистике, вспоминая про японский.
Не забывайте, что для заглавной и строчной буквы нужно придумать свой код, есть запятые, тире и так далее.
Чем больше в таблице символов, тем длиннее код каждого из них, а значит и вес документа становится больше.
Представьте, если бы одна книга весила 4 Гб! Она бы очень долго загружалась, занимала все свободное место на компьютере. Решение о скачивании представлялось бы делом нелегким.
Если вспомнить о сайтах, то вообще страшно подумать, что бы произошло. Каждая страничка открывалась даже на скоростном оптоволокне по часу с лишним! Думаю, мобильные телефоны можно было бы смело выкидывать. Пользоваться ими на улице даже с 4G? Сомневаюсь.
По этим причинам каждый программист в свое время старался придумать свою таблицу символов. Чтобы было удобно для использования и вес сохранялся оптимальным.
Microsoft, к примеру, для русскоязычного сегмента создали windows-1251. В ней, конечно же, есть свои достоинства и недостатки. Как и у любого другого продукта.
Сейчас уже, лишь 2% всех страниц в интернете написано на 1251. Большинство веб-мастеров используют UTF-8. Почему так?
Два метода, как поменять шифровку в Word
Ввиду того, что текстовый редактор “Майкрософт Ворд” является самым популярным на рынке, конкретно форматы документов, которые присущи ему, можно почаще всего встретить в сети. Они могут различаться только версиями (DOCX либо DOC). Но даже с этими форматами программа может быть несовместима либо же совместима не полностью.
Случаи неправильного отображения текста
Конечно, когда в програмке наотрез отрешаются раскрываться, казалось бы, родные форматы, это поправить чрезвычайно трудно, а то и фактически нереально. Но, бывают случаи, когда они открываются, а их содержимое нереально прочитать. Речь на данный момент идет о тех вариантах, когда заместо текста, кстати, с сохраненной структурой, вставлены какие-то закорючки, “перевести” которые невозможно.
Эти случаи почаще всего соединены только с одним – с неправильной шифровкой текста. Поточнее, естественно, будет огласить, что шифровка не неправильная, а просто иная. Не воспринимающаяся програмкой. Любопытно еще то, что общего эталона для шифровки нет. То есть, она может различаться в зависимости от региона. Так, создав файл, к примеру, в Азии, быстрее всего, открыв его в Рф, вы не можете его прочитать.
В данной для нас статье речь пойдет конкретно о том, как поменять шифровку в Word. Кстати, это понадобится не лишь только для исправления вышеописанных “неисправностей”, но и, напротив, для намеренного неверного кодировки документа.
Определение
Перед рассказом о том, как поменять шифровку в Word, стоит отдать определение этому понятию. На данный момент мы попробуем это сделать обычным языком, чтоб даже дальний от данной нам темы человек все понял.
Зайдем издалека. В “вордовском” файле содержится не текст, как почти всеми принято считать, а только набор чисел. Конкретно они преобразовываются во всем понятные знаки програмкой. Конкретно для этих целей применяется кодировка.
Кодировка – схема нумерации, числовое значение в которой соответствует определенному символу. К слову, шифровка может в себя вмещать не лишь только цифровой набор, но и буковкы, и особые знаки. А ввиду того, что в каждом языке употребляются различные знаки, то и шифровка в различных странах отличается.
Как поменять шифровку в Word. Метод первый
После того, как этому явлению было дано определение, можно перебегать конкретно к тому, как поменять шифровку в Word. 1-ый метод можно выполнить при открытии файла в программе.
В том случае, когда в открывшемся файле вы наблюдаете набор непонятных знаков, это значит, что программа ошибочно определила шифровку текста и, соответственно, не способна его декодировать. Все, что необходимо сделать для корректного отображения каждого знака, – это указать пригодную шифровку для отображения текста.
Говоря о том, как поменять шифровку в Word при открытии файла, для вас нужно сделать следующее:
- Нажать на вкладку “Файл” (в ранешних версиях это клавиша “MS Office”).
- Перейти в категорию “Параметры”.
- Нажать по пт “Дополнительно”.
- В открывшемся меню пролистать окно до пт “Общие”.
- Поставить отметку рядом с “Подтверждать преобразование формата файла при открытии”.
- Нажать”ОК”.
Итак, полдела изготовлено. Скоро вы узнаете, как поменять шифровку текста в Word. Сейчас, когда вы будете открывать файлы в програмке “Ворд”, будет появляться окно. В нем вы можете поменять шифровку открывающегося текста.
Выполните последующие действия:
- Откройте двойным кликом файл, который нужно перекодировать.
- Кликните по пт “Кодированный текст”, что находится в разделе “Преобразование файла”.
- В появившемся окне установите переключатель на пункт “Другая”.
- В выпадающем перечне, что размещен рядом, определите подходящую кодировку.
- Нажмите “ОК”.
Если вы избрали верную шифровку, то опосля всего проделанного раскроется документ с понятным для восприятия языком. В момент, когда вы выбираете шифровку, вы сможете поглядеть, как будет смотреться будущий файл, в окне “Образец”. Кстати, ежели вы думаете, как поменять шифровку в Word на MAC, для этого необходимо выбрать из выпадающего перечня соответственный пункт.
Способ второй: во время сохранения документа
Суть второго метода достаточно проста: открыть файл с неправильной шифровкой и сохранить его в пригодной. Делается это последующим образом:
- Нажмите “Файл”.
- Выберите “Сохранить как”.
- В выпадающем перечне, что находится в разделе “Тип файла”, выберите “Обычный текст”.
- Кликните по “Сохранить”.
- В окне преобразования файла выберите предпочитаемую шифровку и нажмите “ОК”.
Теперь вы понимаете два метода, как можно поменять шифровку текста в Word. Надеемся, что эта статья посодействовала для вас в решении вопроса.
Исправление отображения кириллицы с помощью настроек языка и региональных стандартов Windows 10
Самый простой и чаще всего работающий способ убрать кракозябры и вернуть русские буквы в Windows 10 — исправить некоторые неправильные настройки в параметрах системы.
Для этого потребуется выполнить следующие шаги (примечание: привожу также названия нужных пунктов на английском, так как иногда необходимость исправить кириллицу возникает в англоязычных версиях системы без нужды менять язык интерфейса).
После перезагрузки проверьте, была ли решена проблема с отображением русских букв в интерфейсе программ и (или) документах — обычно, кракозябры бывают исправлены после этих простых действий.
Как исправить поврежденную кодировку символов (поврежденный текст) в Microsoft Word
Что такое повреждение символов текста?
Люди, которые активно работают с файлами Plain Text, имеющими суффикс с расширением .TXT, будут иногда сталкиваться с документами, показывающими искаженный текст вместо ожидаемого. Это явление часто происходит, когда поврежденный текстовый документ написан на иностранном языке, который не использует латинский алфавит, но может случиться для всех файлов, если есть несоответствия в настройках, использованных при сохранении файла. Повреждение символа происходит, когда в файле сохранения используется кодировка файла по умолчанию, отличная от программы конечного пользователя. Большинство компьютерных программ по умолчанию используют кодировку UTF-8, но иностранные символы обычно также имеют одну или несколько систем кодирования, зависящих от языка. Например, азиатские языки используют 16-битную систему кодирования; следовательно, когда документ открывается на машине, которая использует 8-битную систему (например, UTF-8), текст будет заменен искаженными символами.
Будьте уверены, поврежденный текст не потерян.Есть много способов исправить поврежденную кодировку символов, в том числе с помощью специального программного обеспечения, созданного для этого конкретного сценария. Однако, если вы хотите исправить только один или два документа, загрузка и установка нового программного обеспечения может стать проблемой. Здесь я покажу вам, как исправить эти поврежденные текстовые файлы в Microsoft Word, который, вероятно, уже установлен на компьютерах под управлением операционной системы Windows.
Если вы используете компьютер Windows, скорее всего, у вас уже установлен Microsoft Word.Microsoft Word имеет встроенный преобразователь кодировки символов, который можно использовать для сохранения файла в нужной кодировке.
Это исправление будет работать с Microsoft Word 2003 и выше.
Windows по умолчанию открывает простые текстовые файлы (с расширением .txt) с помощью программы «Блокнот». Чтобы открыть поврежденный документ в Microsoft Word:
1. Щелкните правой кнопкой мыши документ
2. Выберите «Открыть с помощью»
3. Выберите «Слово»
Диалоговое окно «Преобразовать файл» должно открываться автоматически при обнаружении файла с поврежденной кодировкой.Выберите «Закодированный текст» из списка вариантов и нажмите «ОК».
Если диалоговое окно не появилось, его необходимо запустить вручную. Перейдите в «Файл» -> «Параметры» -> «Дополнительно» и прокрутите вниз, пока не дойдете до раздела «Общие». В разделе «Общие» установите флажок «Подтверждать преобразование формата файла при открытии». Закройте Word и снова откройте поврежденный документ, и появится диалоговое окно.
Диалоговое окно выбора кодировки должно автоматически предлагать правильную кодировку.Если это не так, вы можете вручную выбрать кодировку из списка.
Выберите «Автоматический выбор», если вы не уверены в исходной кодировке, или выберите из списка, если вы знаете язык, на котором находится файл. Вы сможете проверить, исправлен ли поврежденный файл, в окне предварительного просмотра.
Восстановленный текст теперь можно прочитать в Microsoft Word, но он все еще может отображаться как поврежденный в программном обеспечении для обработки обычного текста, поскольку многие из них не написаны для обработки специальной кодировки символов. Чтобы этого не произошло, лучше всего сохранить документ в обычной текстовой кодировке, такой как UTF-8 или UTF-16.
Для этого щелкните вкладку «Файл» в верхнем левом углу документа и выберите «Сохранить как» из списка. Выберите папку для сохранения и выберите «Обычный текстовый документ» в качестве формата файла. Нажмите «Сохранить».
Откроется новое диалоговое окно «Преобразование файла». Из списка выберите кодировку для окончательного документа. В поле предварительного просмотра будут выделены слова, которые не будут правильно сохранены, красным цветом, поэтому постарайтесь выбрать кодировку, которая соответствует документу. В случае сомнений лучше всего использовать формат Unicode в качестве кодировки, так как он разработан с учетом всех мировых систем письма.
Наконец, нажмите «ОК», чтобы сохранить исправленный документ.
Ваш документ теперь должен правильно отображаться в выбранной вами программе обработки обычного текста, например в Блокноте.
Изменение кодировки в программе «Notepad ++»
Подобное приложение используется многими программистами для создания сайтов, различных приложений и многого другого
Поэтому очень важно сохранять и создавать файлы, используя необходимую кодировку. Для того, чтобы настроить нужный вариант для пользователя, следует:
Шаг 1. Запустить программу и в верхнем контекстном меню выбрать вкладку «Кодировки».

Шаг 2. В выпадающем списке пользователю требуется выбрать из списка необходимую для него кодировку и щелкнуть на нее.

Шаг 3
Правильность проведения процедуры легко проверить, обратив внимание на нижнюю панель программы, которая будет отображать только что измененную кодировку

Важно! Перед началом работы в «Notepad ++» в первую очередь рекомендуется проверить установленную кодировку. При необходимости ее нужно изменить при помощи инструкции, приведенной ранее
Смена кодировки текста в Microsoft Word

Набор символов, которые мы видим на экране при открытии документа, называется кодировкой. Когда она выставлена неправильно, вместо понятных и привычных букв и цифр вы увидите бессвязные символы.
Эта проблема часто возникала на заре развития технологий, но сейчас текстовые процессоры умеют сами автоматически выбирать подходящие комплекты. Свою роль сыграло появление и развитие utf-8, так называемого Юникода, в состав которого входит множество самых разных символов, в том числе русских.
Документы в такой кодировке не нуждаются в смене и настройке, так как показывают текст правильно по умолчанию.
Современные текстовые редакторы определяют кодировку при открытии документа
С другой стороны, такая ситуация всё же иногда случается. И получить нечитаемый документ очень досадно, особенно если он важный и нужный. Как раз для таких случаев в Microsoft Word есть возможность указать для текста кодировку. Это вернёт его в читаемый вид.
Заключение
Вопрос смены кодировки в Вордовских документах перед рядовыми пользователями встаёт не так уж часто.
Как правило, текстовый процессор может сам автоматически определить требуемый для корректного отображения набор символов и показать текст в читаемом виде.
Но из любого правила есть исключения, так что нужно и полезно уметь сделать это самому, благо, реализован процесс в Word достаточно просто.
Здесь пользователю придётся выполнить всё те же действия, так что эта статья может помочь не только работающим в Ворде.
Унификация правил настройки для всех программ офисного пакета Microsoft помогает не запутаться в них при работе с любым видом документов, будь то тексты, таблицы или презентации.
https://www.youtube.com/watch?v=f7HZDAC0ePU
Напоследок нужно сказать, что не всегда стоит обвинять кодировку. Возможно, всё гораздо проще. Дело в том, что многие пользователи в погоне за «красивостями» забывают о стандартизации.
Если такой автор выберет установленный у него шрифт, наберёт с его помощью документ и сохранит, у него текст будет отображаться корректно. Но когда этот документ попадёт к человеку, у которого такой шрифт не установлен, то на экране окажется нечитаемый набор символов.
Это очень похоже на «слетевшую» кодировку, так что легко ошибиться. Поэтому перед тем как пытаться раскодировать текст в Word, сначала попробуйте просто сменить шрифт.
Базы банных
Когда речь идет о php, все вообще страшно. Я уже рассказывал про базы данных, они используются для ускорения работы сайта. Обычно, вы к ним не обращаетесь, но когда появляется необходимость в переносе сайта становится не по себе.
Сложности случаются у всех, не важно какой у вас опыт работы, стаж и выслуга лет. Некоторые странички в базе могут содержать в себе все доступные символы для виндовс-1251, другие, к примеру, в шаблонах страниц, в другой кодировке
Пока не нужен перенос все работает и функционирует, хоть и не совсем правильно. Но после переезда начинаются неприятности. В идеале вы должны использовать либо только УТФ, либо виндовс-1251, но по факту всегда и у всех случаются вот такие недочеты.
Чтобы расшифровка согласовалась необходимо вписать код mysql_query(«SET NAMES cp1251»). В этом случае преобразование будет осуществлять по другому протоколу – cp1251.