Html кодировки
Содержание:
- Htaccess
- Недостатки и достоинства
- 1251 – кодовая страница Windows
- Сложные решения
- Почему до сих пор используется 1251
- Немного теории
- Русский текст в консоли
- Решение проблемы
- 866 – кодовая страница DOS
- Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
- Подробное описание
- Рассмотрим пример перекодировки текста из UTF-8 в windows-1251 и обратно
- Как исправить иероглифы Windows 10 путем изменения кодовых страниц
- Chcp 1251 что это: кодировка виндовс
- Кодировки стандарта UNICODE
- Кодировка UNICODE
- Неправильная кодировка HTML страниц
Htaccess
Если на сайте вы настойчиво решили использовать именно 1251, то вам следует найти или создать файл htaccess. Он отвечает за настройки конфигурации. В него придется добавить еще три строчки, чтобы все сошлось.
DefaultLanguage ru; AddDefaultCharset windows-1251; php_value default_charset “cp1251”
Я все же настоятельно рекомендую вам задумать о использовании UTF-8. Он более популярен, прост и богат
Какие бы решения вы не приняли сейчас, важно, чтобы впоследствии можно было все исправить. Добавить англоязычную версию сайта на этой кодировке будет в разы проще
Ничего не нужно исправлять.
Решение остается за вами. Подписывайтесь на рассылку, чтобы узнавать как можно быстрее создавать правильные сайты, где учиться, чтобы не повторять чужих ошибок, а также какие блоггеры получают больше посетителей.
До новых встреч и удачи в ваших начинаниях.
Недостатки и достоинства
UTF-8, в отличие от windows-1251 универсальная кодировка, в ней содержатся буквы различных алфавитов. Существует даже UTF-128, где есть вообще все языки – теулу, суахили, лаосский, мальтийский и так далее.

UTF-8 победнее, буквы занимают в разы меньше места и занимают всего один байт памяти, как и в 1251. В УТФ есть редкие символы из других языков или специальные символы. Они-то и весят по 5-6 байтов, но в документе используются крайне редко.
Когда вы создаете html документ для сайта, то указываете браузерам на какую таблицу им обращать внимание при расшифровке записей. Для этого необходимо вставить в тег head следующие данные
После символов «charset=» идет либо утф, либо виндовс, как в примере ниже
Для этого необходимо вставить в тег head следующие данные. После символов «charset=» идет либо утф, либо виндовс, как в примере ниже.

Если в дальнейшем вы захотите что-то поменять и вставить фразу на албанском, используя эту таблицу расшифровок, то ничего не получится, ведь этого языка кодировка не поддерживает. UTF‑8 без проблем позволит вам это сделать.
Если вас заинтересовало правильное создание сайта, то я могу порекомендовать вам курс Михаила Русакова « Создание и Раскрутка сайта от А до Я ».

Он содержит в себе очень много – 256 уроков, затрагивающих HTML, CSS, JavaScript, PHP, MySQL и XML. Помимо языков программирования вы сможете понять как монетизировать сайт, то есть скорее и больше получать прибыль. Один из немногих курсов, в котором было бы так подробно разъяснено все, что нужно.
1251 – кодовая страница Windows
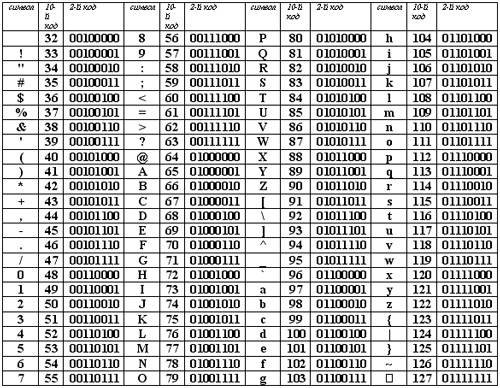
| 128 Ђ | 144 Ђ | 160 | 176 ° | 192 А | 208 Р | 224 а | 240 р |
| 129 Ѓ | 145 ‘ | 161 Ў | 177 ± | 193 Б | 209 С | 225 б | 241 с |
| 130 ‚ | 146 ’ | 162 ў | 178 I | 194 В | 210 Т | 226 в | 242 т |
| 131 ѓ | 147 “ | 163 J | 179 i | 195 Г | 211 У | 227 г | 243 у |
| 132 „ | 148 ” | 164 ¤ | 180 ґ | 196 Д | 212 Ф | 228 д | 244 ф |
| 133 … | 149 • | 165 Ґ | 181 μ | 197 Е | 213 Х | 229 е | 245 х |
| 134 † | 150 – | 166 ¦ | 182 ¶ | 198 Ж | 214 Ц | 230 ж | 246 ц |
| 135 ‡ | 151 — | 167 § | 183 · | 199 З | 215 Ч | 231 з | 247 ч |
| 136 € | 152 □ | 168 Ё | 184 ё | 200 И | 216 Ш | 232 и | 248 ш |
| 137 ‰ | 153 | 169 | 185 № | 201 Й | 217 Щ | 233 й | 249 щ |
| 138 Љ | 154 љ | 170 Є | 186 є | 202 К | 218 Ъ | 234 к | 250 ъ |
| 139 | 171 « | 187 » | 203 Л | 219 Ы | 235 л | 251 ы | |
| 140 Њ | 156 њ | 172 ¬ | 188 j | 204 М | 220 Ь | 236 м | 252 ь |
| 141 Ќ | 157 ќ | 173 | 189 S | 205 Н | 221 Э | 237 н | 253 э |
| 142 Ћ | 158 ћ | 174 | 190 s | 206 О | 222 Ю | 238 о | 254 ю |
| 143 Џ | 159 џ | 175 Ï | 191 ї | 207 П | 223 Я | 239 п | 255 я |
Сложные решения
К этим решениям стоит переходить, если проблема никак отказывается уходить и продолжает досаждать. Иероглифы вместо русских букв устройство печатает по причинам, которые будут разобраны ниже.
Дело может быть в системных файлах. Их восстановление может избавить от проблемы.
Открываем командную строку от имени администратора. Вбиваем команду «sfc /scannow» и жмём «Ввод».

Команда «sfc /scannow»
Ждём несколько минут или секунд. Затем проверяем, решилась ли проблема.
Часто такая ошибка появляется из-за драйверов. Принтер печатает иероглифы, поскольку драйверы неправильные или дают сбои. Поэтому можно попробовать их переустановить. Для этого:
Во вкладке Панели управления «Оборудование и звук» находим наш принтер.

Вкладка «Оборудование и звук»
- Нажимаем ПКМ, выбираем «Удалить устройство».
- В «Программах и компонентах» удаляем все программы, связанные с работой нашего аппарата.
- После удаления находим диск, который идёт вместе с устройством печати. Снего заново устанавливаем все необходимые программы и драйверы.
Если диска у вас нет, то Windows 7 или старше, как правило, сама предлагает установить необходимые драйверы, если заново подключить принтер к компьютеру. Если этого не произошло, то стоит зайти на сайт компании-производителя и скачать необходимое ПО самостоятельно.
Проверьте компьютер антивирусом. Причина может крыться во вредоносном ПО.
Вот основные способы разрешения этой проблемы. Как правило, можно ограничиться простыми действиями, поскольку эта ошибка то появляется, то исчезает сама собой.
Почему до сих пор используется 1251
Существует несколько причин, почему 1251 продолжает пользоваться большой популярностью среди разработчиков онлайн ресурсов:
Ввод специальных символов в документах системы windows
- Многие программисты php используют стандартную кодировку, поскольку OC Windows ее поддерживает в режиме по умолчанию. И хотя в последнее время разработчики стали активно внедрять UTF-8, все же 1251 пока не сдает свои активные позиции
- Если брать для примера старую версию MySQL до четвертой, то стоит отметить, что при включении даже тестового режима, вылезало множество ошибок в UTF-8. Только после выпуска 4.1 многие «глюки» были исправлены. Существует категория программистов, которая вовсе остается верна 1251, а их последователи рьяно берут с них пример и даже не собираются использовать нечто другое
- Поскольку один символ в системе 1251 весит меньше (один байт), то вполне логично, что возникает некая экономия в отличие от последнего варианта.
По сравнению с данной кодировкой, UTF-8 считается более оптимальным вариантом, поскольку она может распознать большее количество символов.
- Возможно включение любых знаков из набора Юникода. Кроме того, вполне логично, что здесь поддерживается 100 000 символов против 256. Здесь можно найти от стандартных смайликов до апострофа абсолютно все. Их использование возможно в любом документе. Кроме того, их можно прочитать даже в редакторе, что исключает вероятность появления нечитабельных знаков
- Ранее существовало мнение о том, что современный utf занимает больше места. В итоге оказалось, что символы также весят всего лишь байт. Значит, стоит сделать вывод о том, что увеличение веса странички не происходит и ее использование такое же легкое. Однако, если используется только русский алфавит, то в таком случае размер будет увеличен вдвое, поскольку изначально кириллица не включена в систему
- Система считается одной из самых универсальных, которые уже смогли достать. В таком случае можно создавать сайты для любого населения мира. Можно уже не думать о том, какая кодировка используется, поскольку Юникод является универсальной вещью
- UTF – это оптимальный вариант работы с php страницами.
Важно отметить, что изначально многие разработчики стали использовать 1251. И хотя сейчас тенденции поменялись, последователей именно этой кодировки осталось, а значит она продолжает пользоваться большой популярностью среди пользователей. ,
,
И хотя сейчас тенденции поменялись, последователей именно этой кодировки осталось, а значит она продолжает пользоваться большой популярностью среди пользователей. ,
Кто-то считает, что универсальная utf – это неплохое решение, которое устанавливается для современных ресурсов, но 1251 – это проверенный алгоритм для стран, использующих кириллицу.
Стоит отметить, что в большинстве случаев используют автоматические переключение. Так, например, если понадобится прочитать информацию на иностранном языке или на русском, достаточно просто переключить кодировку на актуальный формат.
Вероятно, что в будущем 1251 станет еще меньше востребованной, а на смену придут новые проверенные системы. Однако сегодня многие все же используют именно ее.
Также важно принять на заметку, что для работы с utf знание английского языка является обязательным условием
Немного теории
Любой документ на компьютере или в интернете, как я уже сказал, хранится в виде двоичного кода. К примеру, если вы используете кодировку ASCII, то буква «К» будет записана как 10001010, а windows 1251 под этим числом скрывается символ – Љ. В итоге, если браузер или программа обратится к другой таблице и считает вместо ASCII коды windows 1251, то читатель увидит совершенно непонятные ему символ.
Логичен вопрос, нафига было придумывать множество таблиц с кодами? Дело в том, что помимо русского алфавита существует еще и английский, немецкий, китайский. По некоторым подсчетам, существует около 200 000 символов. Хотя, я не очень доверяю этой статистике, вспоминая про японский.
Не забывайте, что для заглавной и строчной буквы нужно придумать свой код, есть запятые, тире и так далее.
Чем больше в таблице символов, тем длиннее код каждого из них, а значит и вес документа становится больше.
Представьте, если бы одна книга весила 4 Гб! Она бы очень долго загружалась, занимала все свободное место на компьютере. Решение о скачивании представлялось бы делом нелегким.
Если вспомнить о сайтах, то вообще страшно подумать, что бы произошло. Каждая страничка открывалась даже на скоростном оптоволокне по часу с лишним! Думаю, мобильные телефоны можно было бы смело выкидывать. Пользоваться ими на улице даже с 4G? Сомневаюсь.
По этим причинам каждый программист в свое время старался придумать свою таблицу символов. Чтобы было удобно для использования и вес сохранялся оптимальным.
Microsoft, к примеру, для русскоязычного сегмента создали windows-1251. В ней, конечно же, есть свои достоинства и недостатки. Как и у любого другого продукта.
Сейчас уже, лишь 2% всех страниц в интернете написано на 1251. Большинство веб-мастеров используют UTF-8. Почему так?
Русский текст в консоли
Вывод русского текста
в консоль из пакетного файла .bat, .cmd
представляет иногда трудность.
Почему же так?
Оболочка CMD.exe работает по-умолчанию в кодировке DOS (OEM-866)Блокнот Windows создает файл в кодировке WIN-1251
Как понимаете, получим крякозябры.Выход: использовать специальный редактор, который сохраняет батник в кодировке CP-866.
Из наиболее популярных:
AkelPad
Скачать редактор с
официального сайта.
Скачать
версию с плагинами и подсветкой
Скачать
уже настроенную с плагинами и подсветкой.Чтобы создать новый файл в кодировке DOS:
Меню «
Файл
» -> «
Сохранить как…
» -> из выпадающего списка выбрать «
Кодировка OEM-866
Файл должен иметь расширение
bat
или
cmd
Для себя я настроил AkelPad так, чтобы он всегда сохранял в кодировке OEM-866 (Настройки -> Параметры -> Кодировка по-умолчанию -> OEM-866.)
Чтобы правильно сконвертировать уже имеющийся в редакторе код с кириллицей:Войти в редактор.1) Ctrl A, скопировать код.2) Удалить код.3) Меню «Кодировки» -> выбрать «Сохранить в DOS-866«.4) Вставить код.5) Сохранить, запустить.
Полезные горячие комбинации клавиш:Запуск скрипта (Ctrl F5)На весь экран (F11)Сохранить (Ctrl S)Открыть в кодировке WIN (Alt W)Открыть в кодировке DOS (Alt D)
Notepad
Скачать
редактор с
официального сайта.Обсуждение редактора на форуме.Чтобы создать новый файл в кодировке DOS:
Меню «
Кодировки
» -> «
Кодировки
» -> «
Кириллица
» -> «
OEM-866
«Файл» -> «
Сохранить как…
» -> пишем имя файла и расширение
bat
или
cmd
->
Сохранить
Чтобы правильно сконвертировать уже имеющийся в редакторе код с кириллицей:Войти в редактор.1) Ctrl A, скопировать код.2) Удалить код.3) Меню «Кодировки» -> «Кодировки» -> «Кириллица» -> «OEM-866«4) Вставить код.5) Сохранить, запустить.
Помните:в редакторе не должно быть видно «крякозябер», иначе это значит: Вы неправильно скопировали код (или открыли в представлении другой кодировки — меню «Вид»).В Windows Vista, 7 часто бывает, что код с форума «портиться» в буфере.Выход: когда копируете код, убедитесь, что включена русская раскладка клавиш, или воспользуйтесь этим твиком # 2.
§
Вывод русского текста
в консоль из пакетного файла .bat, .cmd
представляет иногда трудность.
Почему же так?
Оболочка CMD.exe работает по-умолчанию в кодировке DOS (OEM-866)Блокнот Windows создает файл в кодировке WIN-1251
Как понимаете, получим крякозябры.Выход: использовать специальный редактор, который сохраняет батник в кодировке CP-866.
Из наиболее популярных:
AkelPad
Скачать редактор с
официального сайта.
Скачать
версию с плагинами и подсветкой
Скачать
уже настроенную с плагинами и подсветкой.Чтобы создать новый файл в кодировке DOS:
Меню «
Файл
» -> «
Сохранить как…
» -> из выпадающего списка выбрать «
Кодировка OEM-866
Файл должен иметь расширение
bat
или
cmd
Для себя я настроил AkelPad так, чтобы он всегда сохранял в кодировке OEM-866 (Настройки -> Параметры -> Кодировка по-умолчанию -> OEM-866.)
Чтобы правильно сконвертировать уже имеющийся в редакторе код с кириллицей:Войти в редактор.1) Ctrl A, скопировать код.2) Удалить код.3) Меню «Кодировки» -> выбрать «Сохранить в DOS-866«.4) Вставить код.5) Сохранить, запустить.
Полезные горячие комбинации клавиш:Запуск скрипта (Ctrl F5)На весь экран (F11)Сохранить (Ctrl S)Открыть в кодировке WIN (Alt W)Открыть в кодировке DOS (Alt D)
Notepad
Скачать
редактор с
официального сайта.Обсуждение редактора на форуме.Чтобы создать новый файл в кодировке DOS:
Меню «
Кодировки
» -> «
Кодировки
» -> «
Кириллица
» -> «
OEM-866
«Файл» -> «
Сохранить как…
» -> пишем имя файла и расширение
bat
или
cmd
->
Сохранить
Чтобы правильно сконвертировать уже имеющийся в редакторе код с кириллицей:Войти в редактор.1) Ctrl A, скопировать код.2) Удалить код.3) Меню «Кодировки» -> «Кодировки» -> «Кириллица» -> «OEM-866«4) Вставить код.5) Сохранить, запустить.
Помните:в редакторе не должно быть видно «крякозябер», иначе это значит: Вы неправильно скопировали код (или открыли в представлении другой кодировки — меню «Вид»).В Windows Vista, 7 часто бывает, что код с форума «портиться» в буфере.Выход: когда копируете код, убедитесь, что включена русская раскладка клавиш, или воспользуйтесь этим твиком # 2.
Решение проблемы
В реестре Windows нужно открыть ветку HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage, найти в ней параметры «1250», «1252» и «1253» и установить для каждого из них значение «c_1251.nls». Сделать это можно несколькими способами:
Способ 1
1) открыть «Редактор реестра». Для этого нужно нажать на клавиатуре кнопку «Windows» (обычно с изображением логотипа Windows, находится в нижнем ряду, слева, между кнопками Ctrl и Alt) и, удерживая ее, нажать кнопку «R» (в русской раскладке «К»). Появится окно запуска программ. В нем нужно написать regedit и нажать кнопку «ОК»; 2) последовательно открывая соответствующие папки в левой части «Редактора реестра», зайти в ветку HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage. Это значит, что нужно открыть сначала папку «HKEY_LOCAL_MACHINE», в ней открыть папку «SYSTEM», в ней – «CurrentControlSet» и т.д.; 3) когда доберетесь до раздела «CodePage» и выделите его в левой части «Редактора реестра», в его правой части появится довольно большой список параметров. Нужно отыскать среди них параметры «1250», «1252» и «1253». 4) дважды щелкнуть мышкой по параметру «1250». Откроется окно «Изменение строкового параметра». В нем содержание поля «Значение» нужно изменить на «c_1251.nls» и нажать кнопку «ОК» (см.рис.). Затем аналогичным образом изменить на «c_1251.nls» значение параметров «1252» и «1253». 5) закрыть окно редактора реестра и перезагрузить компьютер. После перезагрузки проблема с неправильным отображением шрифтов должна исчезнуть.
Способ 2
Все указанные выше изменения в системный реестр можно внести немного проще, используя соответствующий REG-файл. REG-файлы (их часто называют твиками реестра) — это такие специальные файлы, при открытии которых все предусмотренные в них изменения вносятся в реестр автоматически. Вам остается только подтвердить эти изменения и перезагрузить компьютер. Открывать REG-файлы необходимо от имени администратора компьютера. Подробнее об этом читайте . Чтобы получить архив с REG-файлом, осуществляющим описанные выше действия, нажмите сюда.
В этой статье рассмотрено, почему вместо русских букв, возникают квадратики, непонятные символы, кракозябры, вопросительные знаки, точки, каракули или кубики в windows 7, vista, XP?
Что делать, чтобы избавиться от этих явлений? Универсального рецепта — нет. Много зависит от версии виндовс, да и самой сборки.
Первая причина, почему такое происходит – сбой кодировок. Нарушается целостность реестра, и происходят сбои. Только не всегда это основной источник.
Часто бывает, что даже на ново установленной операционной системе, после запуска некоторых программ вместо русских букв возникают квадратики, непонятные символы, крякозябры, вопросительные знаки, точки, каракули или кубики.
Если же проблема с цифрами, тогда она быстро , а избавиться от знаков вопросов вместо нормальных букв поможет эта инструкция.

Особенно часто такое случается после установки русификаторов. Народные «умельцы», не учитывают все, а возможно и переводы делают только под одну операциоку.
Возможно и не это главное, если учесть, что все заключаться в кодировке. Может программа, просто не поддерживает определенные буквы.
Хотя это и удивительно, но по умолчанию операционная система windows 7 вместо русских букв в некоторых программа отображает квадратики, непонятные символы, кракозябры, вопросительные знаки, точки, каракули или кубики.
Я всегда после переустановки вношу изменения в реестр, даже если все работает нормально. В будущем проблем с непонятными символами не возникает.
866 – кодовая страница DOS
| 128 А | 144 Р | 160 а | 176 ░ | 192 └ | 208 ╨ | 224 р | 240 ≡Ё |
| 129 Б | 145 С | 161 б | 177 ▒ | 193 ┴ | 209 ╤ | 225 с | 241 ±ё |
| 130 В | 146 Т | 162 в | 178 ▓ | 194 ┬ | 210 ╥ | 226 т | 242 ≥ |
| 131 Г | 147 У | 163 г | 179 │ | 195 ├ | 211 ╙ | 227 у | 243 ≤ |
| 132 Д | 148 Ф | 164 д | 180 ┤ | 196 ─ | 212 ╘ | 228 ф | 244 ⌠ |
| 133 Е | 149 Х | 165 е | 181 ╡ | 197 ┼ | 213 ╒ | 229 х | 245 ⌡ |
| 134 Ж | 150 Ц | 166 ж | 182 ╢ | 198 ╞ | 214 ╓ | 230 ц | 246 ¸ |
| 135 З | 151 Ч | 167 з | 183 ╖ | 199 ╟ | 215 ╫ | 231 ч | 247 » |
| 136 И | 152 Ш | 168 и | 184 ╕ | 200 ╚ | 216 ╪ | 232 ш | 248 ° |
| 137 Й | 153 Щ | 169 й | 185 ╣ | 201 ╔ | 217 ┘ | 233 щ | 249 · |
| 138 К | 154 Ъ | 170 к | 186 ║ | 202 ╩ | 218 ┌ | 234 ъ | 250 ∙ |
| 139 Л | 155 Ы | 171 л | 187 ╗ | 203 ╦ | 219 █ | 235 ы | 251 √ |
| 140 М | 156 Ь | 172 м | 188 ╝ | 204 ╠ | 220 ▄ | 236 ь | 252 ⁿ |
| 141 Н | 157 Э | 173 н | 189 ╜ | 205 ═ | 221 ▌ | 237 э | 253 ² |
| 142 О | 158 Ю | 174 о | 190 ╛ | 206 ╬ | 222 ▐ | 238 ю | 254 ■ |
| 143 П | 159 Я | 175 п | 191 ┐ | 207 ╧ | 223 ▀ | 239 я | 255 |
Русские названия основных спецсимволов:
| Символ | Название |
| ` | гравис, кавычка, обратный машинописный апостроф |
| ` | гравис, кавычка, обратный машинописный апостроф |
тильда ! восклицательный знак
@ эт, коммерческое эт, «собака»
# октоторп, решетка, диез
$ знак доллара
% процент
^ циркумфлекс, знак вставки
& амперсанд
* астериск, звездочка, знак умножения
( левая открывающая круглая скобка
) правая закрывающая круглая скобка
— минус, дефис
_ знак подчеркивания
= знак равенства
+ плюс
левая открывающая квадратная скобка
правая закрывающая квадратная скобка
левая открывающая фигурная скобка
> правая закрывающая фигурная скобка
; точка с запятой
двоеточие
‘ машинописный апостроф, одинарная кавычка
“ двойная кавычка
, запятая
. точка
слэш, косая черта, знак дроби
правая закрытая угловая скобка, знак больше
\ обратный слэш, обратная косая черта
| вертикальная черта
Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
Эти тысячи знаков языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных версиях ASCII. В результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста.
Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить.
В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов.
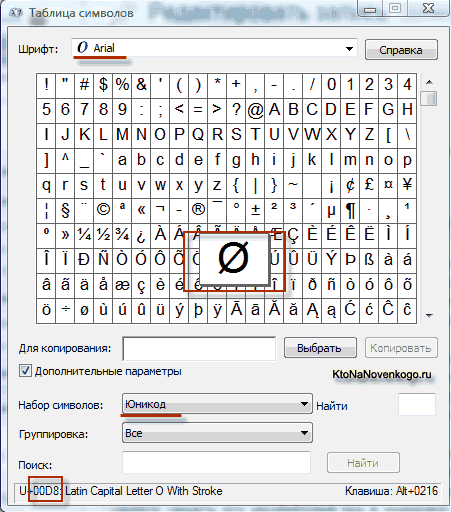
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста.
Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них, после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16).
На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII.
Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. Т.е. базовая часть Аски просто перешла в это детище консорциума Unicode.
В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
Подробное описание
Юникод — это мировой стандарт кодировки символов. Система использует Юникод исключительно для обработки символов и строк. Подробное описание всех аспектов Юникода см. в стандарте Юникода.
Windows поддерживает юникод и традиционные кодировки. традиционные кодировки, такие как Windows кодовые страницы, используют 8-разрядные значения или сочетания 8-разрядных значений для представления символов, используемых в параметрах определенного языка или географического региона.
По умолчанию PowerShell использует набор символов Юникода. Однако несколько командлетов имеют параметр кодирования , который может указывать кодировку для другой кодировки. Этот параметр позволяет выбрать конкретную кодировку символов, необходимую для взаимодействия с другими системами и приложениями.
Следующие командлеты имеют параметр Encoding :
- Microsoft.PowerShell.Management
- Add-Content
- Get-Content
- Set-Content
- Microsoft.PowerShell.Utility
- Export-Clixml
- Export-Csv
- Export-PSSession
- Format-Hex
- Import-Csv
- Out-File
- Select-String
- Send-MailMessage
Рассмотрим пример перекодировки текста из UTF-8 в windows-1251 и обратно
ob_start();
var_dump( ‘Марат’ );
echo ob_get_clean();
Теперь попробуем перекодировать строку прямо внутри :
ob_start();
var_dump(iconv(«UTF-8», «windows-1251», ‘Марат’)) ;
echo ob_get_clean() ;
Результат подсчета знаков верный, но видим что слово не было перекодировано обратно :
string(5) «»
Исправим:
ob_start();
var_dump(iconv(«UTF-8», «windows-1251», ‘Марат’)) ;
echo iconv(«windows-1251», «UTF-8», ob_get_clean());
Результат :
string(5) «Марат»
Итак… вы видели процесс кодировки и перекодировки текста из utf-8 в windows 1251, а потом обратно!
Вы наверное подумали :
Что за дичь здесь происходит!? Это не дичь! Когда ты внутри, а не снаружи, то все кажется не простым, а очень простым.
И чем больше ты в теме, это просто, как есть, пить, дышать… просто не задумываешься…
Я не говорю, что всегда так, иногда бывает очень трудно какаю-то задачку решить…
Как исправить иероглифы Windows 10 путем изменения кодовых страниц
Кодовые страницы представляют собой таблицы, в которых определенным байтам сопоставляются определенные символы, а отображение кириллицы в виде иероглифов в Windows 10 связано обычно с тем, что по умолчанию задана не та кодовая страница и это можно исправить несколькими способами, которые могут быть полезны, когда требуется не изменять язык системы в параметрах.
С помощью редактора реестра
Первый способ — использовать редактор реестра. На мой взгляд, это самый щадящий для системы метод, тем не менее, рекомендую создать точку восстановления прежде чем начинать. Совет про точки восстановления относится и ко всем последующим способам в этом руководстве.
Обычно, это исправляет проблему с отображением русских букв. Вариация способа с помощью редактора реестра (но менее предпочтительная) — посмотреть на текущее значение параметра ACP (обычно — 1252 для изначально англоязычных систем), затем в том же разделе реестра найти параметр с именем 1252 и изменить его значение с c_1252.nls на c_1251.nls.
Путем подмена файла кодовой страницы на c_1251.nls
Второй, не рекомендуемый мной способ, но иногда выбираемый теми, кто считает, что правка реестра — это слишком сложно или опасно: подмена файла кодовой страницы в C:\ Windows\ System32 (предполагается, что у вас установлена западно-европейская кодовая страница — 1252, обычно это так. Посмотреть текущую кодовую страницу можно в параметре ACP в реестре, как было описано в предыдущем способе).
После перезагрузки Windows 10 кириллица должна будет отображаться не в виде иероглифов, а как обычные русские буквы.
Chcp 1251 что это: кодировка виндовс
На днях пришлось решать небольшую проблему с плохой восприимчивостью комплекта Denwer к кодировки UTF-8. Проблема, честно говоря, оказалась пустяковая, и была решена минут за 15, 10 из которых заняло использование Гугла. В этом время, исследуя различные форумы, я заметил, что для многие не могут разобраться с этой проблемой достаточно долго. Кроме того, понял, что многих интересует зачем вообще использовать UTF-8, если есть прекрасная такая “русская” кодировка Windows-1251. Вот и решил написать пару постов на эту тему. Начну я с общего описания данных кодировок, а продолжу, непосредственно, описанием решения проблемы использования UTF-8 на пакете Denwer.
Не так давно, в связи со сложившимися обстоятельствами, решил отказаться от кодировки Windows-1251, с которой работал очень давно, и целиком и полностью перейти на UTF-8. Все причины перехода раскрывать не буду, но основные из них:
- большинство современных веб-платформ по-умолчанию работают именно на ней;
- её очень удобно использовать для создания мультиязычных проектов;
- набор используемых в кодировки символов около 100000;
- кодировка универсальная, т.е. русские символы и в Никарагуа остаются русскими.
Далее постараюсь написать несколько слов об основных отличиях кодировок Windows-1251 и UTF-8, а так же, в качестве бонуса, примеры объявления кодировки в HTML, PHP и для работы с базами данных MySQL.
Немного теории
Windows-1251 – набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста; она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского.
UTF-8 – в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт.
Основные отличия кодировок
Главное отличие кодировок – это используемый набор символов. В UTF-8 гораздо больше количество символов возможно представить, чем в Windows- 1251.
Кодировка Windows- 1251 однобайтовая, т.е. представить в ней можно только 255 символов. Для кириллицы, впрочем, этого вполне достаточно, именно поэтому однобайтовые кодировки до сих пор так массово применяются.
Символ в кодировке UTF-8 может кодироваться аж 6 байтами (пока используется только 4 и больше не планируется). Для русского языка, например, символ занимает 2 байта. Все символы, которые есть в таблице символов – поддерживаются этой кодировкой. К примеру, если вам нужен знак копирайта (), то вам не нужно искать особый шрифт или же изображать символов в графическом формате.
Плюсы UTF-8:
- UTF-8 позволяет работать одновременно с несколькими языками, т.е. выдавать тексты, в которых используются символы разных алфавитов и даже иероглифы. С использованием кодировки 1251 это невозможно;
- использование UTF-8 позволяет отказаться от кодовых таблиц, трансляций символов и всех прочих извращений, что были ранее с однобайтовыми кодировками;
- Нет кучи кодировок для одного и того же языка, как это было ранее для русского: cp1251, cp866, koi8r, iso8859-5.
Минусы UTF-8…
А есть ли они у этой кодировки вообще? Я знаю только разных мифах и легендах на эту тему, вот некоторые из них: “У UTF-8 есть проблемы со старыми браузерами” – маловероятно… Во всяком случае, если под старыми не подразумевают Lynx и Mosaic _); “С UTF-8 возникают проблемы на сервере” – ну да, если сервер по-умолчанию пытается определить другую кодировку. Но это не минус кодировки, уж точно…
Кодировки стандарта UNICODE
Юникод (англ. Unicode) — стандарт кодирования символов, позволяющий представить знаки почти всех письменностей мира, и специальных символов. Представляемые в юникоде символы кодируются целыми числами без знака. Юникод имеет несколько форм представления символов в компьютере: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). (Англ. Unicode transformation format — UTF).UTF-8 — это в настоящее время распространённая кодировка, которая нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий из символов Unicode с номерами меньше 128 (область с кодами от U+0000 до U+007F), содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F.
Кодировка UTF-8 является универсальной и имеет внушительный резерв на будущее. Это делает ее наиболее удобной кодировкой для использования в интернете.
HTML Символы Кодирование URL
Кодировка UNICODE
Юникод (Unicode) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода».
В Unicode используются 16-битовые (2-байтовые) коды, что позволяет представить 65536 символов.
Применение стандарта Unicode позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становится ненужным переключение кодовых страниц.
Тип кодировки задается в свойствах проекта Microsoft Visual Studio:


Для перекодирования строки в формат Unicode без изменения кодировки файла используется макроопределение _T(“строка”)
Неправильная кодировка HTML страниц
Создадим тестовый файлик:
sudo gedit /var/www/html/encoding.html
Скопируем в него следующий HTML код, в котором отсутствует указание кодировки и посмотрим, какие проблемы могут с ним возникнуть и как их решить:
<html>
<head>
<title>Проверка кодировки</title>
</head>
<body>
<h1>Тестовый файл для проверки кодировки</h1>
</body>
</html>
Откроем этот файл в браузере http://localhost/encoding.html
Как можно видеть, кодировка браузером определена неправильно:

Имеется несколько способов исправить эту ситуацию. Начнём с самого простого – явно указать кодировку для веб-страницы. Это делается метатегом, который должен быть расположен внутри тэга head:
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
Добавим эту строку к нашему тестовому файлику, чтобы получилось так:
<html>
<head>
<title>Проверка кодировки</title>
<meta http-equiv="content-type" content="text/html; charset=utf-8" />
</head>
<body>
<h1>Тестовый файл для проверки кодировки</h1>
</body>
</html>
Как мы можем убедиться на следующем скриншоте, проблема решена:

Если кодировка вашего файла отличается от UTF-8, то вместо неё поставьте windows-1251 или ту, которая соответствует кодировке веб-страницы. Чтобы научиться определять кодировку файлов, посмотрите эту инструкцию.
Это был самый простой способ исправления проблемы с кодировкой – без изменения настроек сервера.
Вернём наш тестовый файл в исходное состояние и продолжим изучение способов указания кодировки.
Если файлы .htaccess включены настройками Apache, то эти файлы можно использовать чтобы указывать кодировку отправляемых веб-сервером страниц. Чтобы включить поддержку файлов .htaccess в конфигурационном файле Apache ( /etc/apache2/apache2.conf ) найдите группу строк
<Directory /var/www/> Options Indexes FollowSymLinks AllowOverride None Require all granted </Directory>
И в ней замените
AllowOverride None
на
AllowOverride All
После этого сервер нужно перезапустить.
sudo systemctl restart apache2.service
Файл .htaccess должен быть размещён в той же директории, что и сайт. Мой сайт размещён в корневой директории веб-сервера. Если у вас также, то теперь в папке /var/www/html/ создайте файл .htaccess и добавьте в него директиву AddDefaultCharset после которой укажите желаемую кодировку. Примеры
AddDefaultCharset UTF-8
ИЛИ
AddDefaultCharset windows-1251
Можно указать кодировку, которая будет применена только к файлам определённого формата:
AddCharset utf-8 .atom .css .js .json .rss .vtt .xml
Набор файлов может быть любым, например:
AddCharset utf-8 .html .css .php .txt .js
Следующий вариант является альтернативным и также позволяет устанавливать кодировку для файлов определённого типа, для него нужно, чтобы был включён mod_headers:
<Files ~ "\.html?$">
Header set Content-Type "text/html; charset=utf-8"
</Files>
Ещё один вариант, который также можно использовать в файле .htaccess для установки кодировки UTF-8:
IndexOptions +Charset=utf-8
Если сайт на PHP, то дополнительно может понадобиться продублировать кодировку с php_value default_charset:
AddDefaultCharset windows-1251 php_value default_charset "cp1251"
Можно вместо создания файла .htaccess установить кодировку в конфигурационном файле веб-сервера. Для Apache CentOS/Fedora это файл httpd.conf, а на Debian/Ubuntu это файл apache2.conf. Добавьте следующую строку для установки кодировки и перезапустите веб-сервер, чтобы изменения вступили в силу:
AddDefaultCharset UTF-8