Найти удаленный сайт
Содержание:
- r-tools.org
- Why Donate?
- Media collections
- How to download all page changes from a web archive
- Что такое Wayback Machine и Архивы Интернета
- [править] Ссылки
- How to find out all the pages of a site that are saved in the Internet archive
- Как использовать веб-архив?
- Поиск сайтов в Wayback Machine
- Screenshots
- Принцип работы веб-архива
- Качаем сайт с web.archive.org
- Что такое веб-архив
r-tools.org
Первое, что бросается в глаза дизайн сайта стороват. Ребята, пора обновлять!
Плюсы:
- Подходит для парсинга сайтов у которых мало html страниц и много ресурсов другого типа. Потомучто они рассчитывают цену по html страницам
- возможность отказаться от сайта, если качество не устроило. После того как система скачала сайт, вы можете сделать предпросмотр и отказаться если качество не устроило, но только если еще не заказали генерацию архива. (Не проверял эту функцию лично, и не могу сказать на сколько хорошо реализован предпросмотр, но в теории это плюс)
- Внедрена быстрая интеграция сайта с биржей SAPE
- Интерфейс на русском языке
Минусы:
- Есть демо-доступ — это плюс, но я попробовал сделать 4 задания и не получил никакого результата.
- Высокие цены. Парсинг 25000 стр. обойдется в 2475 руб. , а например на Архивариксе 17$. Нужно учесть, что r-tools считает html страницы, архиварикс файлы. Но даже если из всех файлов за 17$ только половина html страницы, все равно у r-tools выходит дороже. (нужно оговориться, что считал при $=70руб. И возможна ситуация, когда r-tools будет выгоден написал про это в плюсах)
Why Donate?
For donations of 50 or more items, the Archive can create a collection to both honor the donor and make their donation accessible all in one place. “The ability to access all of their media in one place really reassures our donors that they will still have access to their items even once they’re no longer in their physical possession,” said Rosenberg. Some stories behind major contributions are covered by the Archive in its blog.
Better World Books, a socially responsible bookstore that has a longstanding relationship with the Internet Archive, regularly donates books for preservation and digitization. It receives many of its books from library partners around the world. The Archive accepts many materials that BWB will not.
Internet Archive team members having fun with the task of packing & shipping an entire library collection from Bay State College.
“We love more than anything to get large collections—entire intellectual units, such as a reference collection that is curated,” said Chris Freeland, a librarian who works at the Archive. “It helps us round out our collection, and helps our patrons. If someone has a collection that no longer fits their collection development priorities, think of Better World Book or the Internet Archive for those materials.”
The Archive is open to over-sized items, such as maps, and books that do not have to have an ISBN number. What about loose periodicals? The Archive does not want a few scattered issues but does have interest in long runs of a magazine.
Once digitized, patrons with print disabilities can access the materials and some are selected to be accessible via Controlled Digital Lending and for machine learning research. Together, we can achieve long term preservation and access to our collective cultural legacy.
Media collections
In addition to Web archives, the Internet Archive maintains extensive collections of digital media that are either public domain or licensed under a license that allows redistribution, such as the Creative Commons License. The media are organized into collections by media type (moving images, audio, text, etc.), and into sub-collections by various criteria. Each of main collection includes an «Open Source» sub-collection where general contributions by the public can be stored.
Moving image collection
Aside from feature films, IA’s Moving Image collection includes: newsreels; classic cartoons; pro- and anti-war propaganda; Skip Elsheimer’s «A.V. Geeks» collection; and ephemeral material from Prelinger Archives, such as advertising, educational and industrial films and amateur and home movie collections.
IA’s Brick Films collection contains stop-motion animation filmed with LEGO bricks, some of which are ‘remakes’ of feature films. The Election 2004 collection is a non-partisan public resource for sharing video materials related to the 2004 United States Presidential Election. The Independent News collection includes sub-collections such as the Internet Archive’s World At War competition from 2001, in which contestants created short films demonstrating «why access to history matters.» Among their most-downloaded video files are eyewitness recordings of the devastating 2004 Indian Ocean earthquake. The September 11th Television Archive contains archival footage from the world’s major television networks as the attacks of September 11th, 2001 unfolded on live television.
Some of the films available on the Internet Archive are:
|
|
Audio collection
The audio collection includes music, audio books, news broadcasts, old time radio shows and a wide variety of other audio files.
The Live Music Archive sub-collection includes 40,000 concert recordings from independent artists, as well as more established artists and musical ensembles with permissive rules about recording their concerts such as the Grateful Dead.
Texts collection
The texts collection includes digitized books from various libraries around the world as well as many special collections. As of May 2008, the Internet Archive operated 13 scanning centers in great libraries, digitizing about 1000 books a day, financially supported by libraries and foundations.
Between about 2006 and 2008 Microsoft Corporation had a special relationship with Internet Archive texts through its Live Search Books project, scanning over 300,000 books which were contributed to the collection, as well as financial support and scanning equipment. On May 23, 2008 Microsoft announced it would be ending the Live Book Search project and no longer scanning books. Microsoft will be making its scanned books available without contractual restriction and making the scanning equipment available to its digitization partners and libraries to continue digitization programs. Retrieved June 15, 2008.
How to download all page changes from a web archive
If you are not interested in the whole site, but a specific page, but you need to track all the changes on it, then use the Waybackpack program.
To install Waybackpack on Kali Linux
sudo apt install python3-pip sudo pip3 install waybackpack
To install Waybackpack on BlackArch
sudo pacman -S waybackpack
Usage:
waybackpack (-d DIR | --list)
url
Options:
positional arguments:
url The URL of the resource you want to download.
optional arguments:
-h, --help show this help message and exit
--version show program's version number and exit
-d DIR, --dir DIR Directory to save the files. Will create this directory if it doesn't already exist.
--list Instead of downloading the files, only print the list of snapshots.
--raw Fetch file in its original state, without any processing by the Wayback Machine or waybackpack.
--root ROOT The root URL from which to serve snapshotted resources. Default: 'https://web.archive.org'
--from-date FROM_DATE
Timestamp-string indicating the earliest snapshot to download. Should take the format YYYYMMDDhhss, though you can omit as many of the trailing digits as you like.
E.g., '201501' is valid.
--to-date TO_DATE Timestamp-string indicating the latest snapshot to download. Should take the format YYYYMMDDhhss, though you can omit as many of the trailing digits as you like.
E.g., '201604' is valid.
--user-agent USER_AGENT
The User-Agent header to send along with your requests to the Wayback Machine. If possible, please include the phrase 'waybackpack' and your email address. That
way, if you're battering their servers, they know who to contact. Default: 'waybackpack'.
--follow-redirects Follow redirects.
--uniques-only Download only the first version of duplicate files.
--collapse COLLAPSE An archive.org `collapse` parameter. Cf.: https://github.com/internetarchive/wayback/blob/master/wayback-cdx-server/README.md#collapsing
--ignore-errors Don't crash on non-HTTP errors e.g., the requests library's ChunkedEncodingError. Instead, log error and continue. Cf.
https://github.com/jsvine/waybackpack/issues/19
--quiet Don't log progress to stderr.
For example, to download all copies of the main page of the suip.biz website, starting from the date (—to-date 2017), these pages should be placed in the folder (-d /home/mial/test), while the program must follow HTTP redirects (—follow-redirects):
waybackpack suip.biz -d ./suip.biz-copy --to-date 2017 --follow-redirects
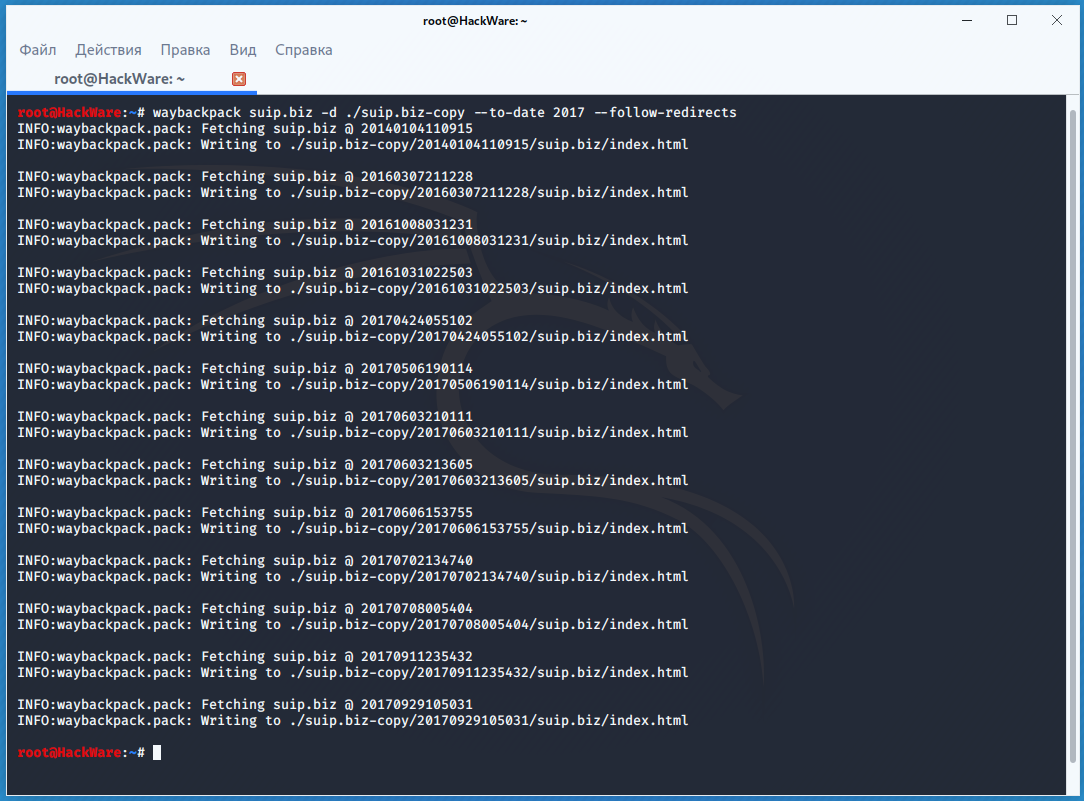
Directory structure:
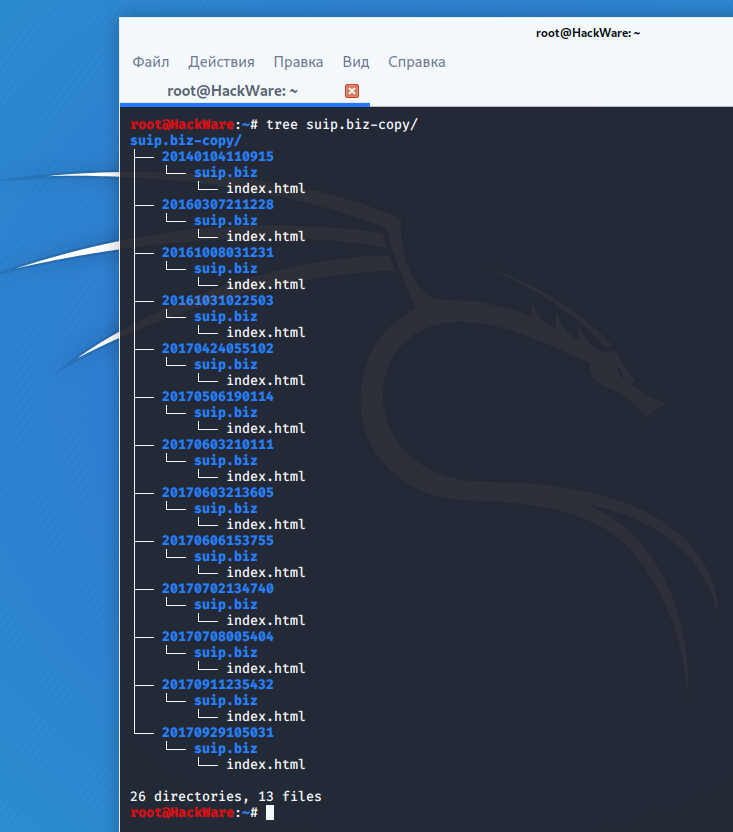
To display a list of all available copies in the Internet archive (—list) for the specified site (hackware.ru):
waybackpack hackware.ru --list
Что такое Wayback Machine и Архивы Интернета
В этой статье мы рассмотрим Веб Архивы сайтов или Интернет архивы: как искать удалённую с сайтов информацию, как скачать больше несуществующие сайты и другие примеры и случаи использования.
Принцип работы всех Интернет Архивов схожий: кто-то (любой пользователь) указывает страницу для сохранения. Интернет Архив скачивает её, в том числе текст, изображения и стили оформления, а затем сохраняет. По запросу сохранённые страницу могут быть просмотрены из Интернет Архива, при этом не имеет значения, если исходная страница изменилась или сайт в данный момент недоступен или вовсе перестал существовать.
Многие Интернет Архивы хранят несколько версий одной и той же страницы, делая её снимок в разное время. Благодаря этому можно проследить историю изменения сайта или веб-страницы в течение всех лет существования.
В этой статье будет показано, как находить удалённую или изменённую информацию, как использовать Интернет Архивы для восстановления сайтов, отдельных страниц или файлов, а также некоторые другие случае использования.
Wayback Machine — это название одного из популярного веб архива сайтов. Иногда Wayback Machine используется как синоним «Интернет Архив».
[править] Ссылки
| Веб-архив относится к теме «Интернет» | |||||||||||||||||||||||
|
How to find out all the pages of a site that are saved in the Internet archive
To obtain links that are stored in the Internet Archive, use the waybackurls program.
This program retrieves all the URLs of the specified domain that Wayback Machine knows about. This can be used to quickly map a site.
How to install waybackurls on Kali Linux
Start by installing Go, to do this, go to the article “How to install Go (compiler and tools) on Linux” and select “Manual installation of the latest version of the Go compiler”.
Then type:
go get github.com/tomnomnom/waybackurls waybackurls --help
How to install waybackurls on BlackArch
sudo pacman -S waybackurls
It can work with a list of domains getting it from standard input. In this list, each domain should be written on a separate line.
The program reads domains from standard input, therefore, to start receiving page addresses of one domain, you need to use a command like that:
echo DOMAIN | waybackurls
To get all the URLs of many sites as DOMAINS.txt, you need to specify a file that lists all domains in the format of one domain per line:
cat DOMAINS.txt | waybackurls
Options:
-dates
show date of fetch in the first column
-no-subs
don't include subdomains of the target domain
To get a list of all the pages Wayback Machine knows about for the suip.biz domain:
echo suip.biz | waybackurls
Как использовать веб-архив?
 Форма для поиска информации на Peeep.us
Форма для поиска информации на Peeep.us
Как уже отмечалось выше, веб-архив — это сайт, который предоставляет определенного рода услуги по поиску в истории. Чтобы использовать проект, необходимо:
- Зайти на специализированный ресурс (к примеру, web.archive.org).
- В специальное поле внести информацию к поиску. Это может быть доменное имя или ключевое слово.
- Получить соответствующие результаты. Это будет один или несколько сайтов, к каждому из которых имеется фиксированная дата обхода.
- Нажатием по дате перейти на соответствующий ресурс и использовать информацию в личных целях.
О специализированных сайтах для поиска исторического фиксирования проектов поговорим далее, поэтому оставайтесь с нами.
Поиск сайтов в Wayback Machine
Wayback Machine
На странице «Internet Archive Wayback Machine» введите в поле поиска URL адрес сайта, а затем нажмите на кнопку «BROWSE HISTORY».
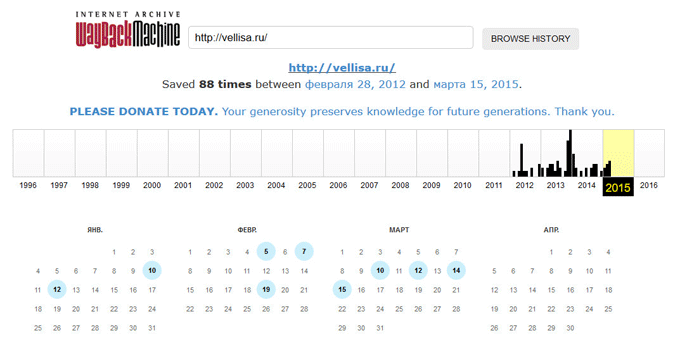
Под полем поиска находится информация об общем количестве созданных архивов для данного сайта за определенный период времени. На шкале времени по годам отображено количество сделанных архивов сайта (снимков сайта может быть много, или, наоборот, мало).
Выделите год, в центральной части страницы находится календарь, в котором выделены голубым цветом даты, когда создавались архивы сайта. Далее нажмите на нужную дату.
Вам также может быть интересно:
- Советские фильмы онлайн в интернете
- Яндекс Дзен — лента персональных рекомендаций
Обратите внимание на то, что при подведении курсора мыши отобразится время создания снимка. Если снимков несколько, вы можете открыть любой из архивов
Сайт будет открыт в том состоянии, которое у него было на момент создания архива.
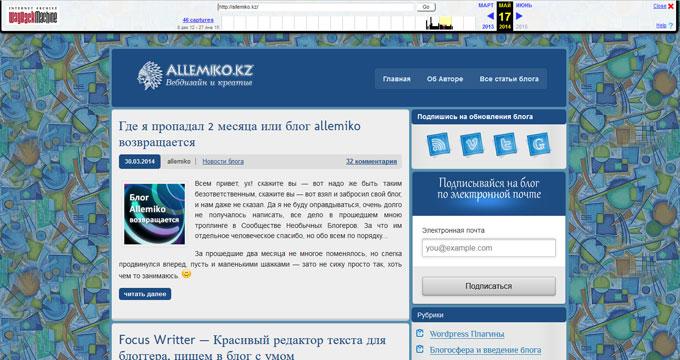
За время существования моего сайта, у него было только два шаблона (темы оформления). На этом изображении вы можете увидеть, как выглядел мой сайт в первой теме оформления.

На этом изображении вы видите сайт моего знакомого, Алема из Казахстана. Данного сайта уже давно нет в интернете, поисковые системы не обнаруживают этот сайт, но благодаря архиву интернета все желающие могут получить доступ к содержимому удаленного сайта.
Screenshots
Screenshots can be a good alternative to Wayback Machine, if you want to see how a website actually looked like in the past. Internet archiving websites, including Wayback Machine, copy the web page code and save it for future reference. However, Screenshots just takes a snapshot of a web page and then archives it.
How it Works
Screenshots use the WHOIS database of DomainTools to find the websites to archive and then use snapshots to make a record of them. The time and frequency of taking snapshots for a particular website depends on how many times it got updated with new content.
If a website gets updated frequently with big changes, then it will also be archived more often and you will find more snapshots of it in Screenshots’ history. However, if a website doesn’t get updated frequently or there are not many changes in the design of the website, then you should expect fewer snapshots.
So far, Screenshots has been able to amass over 250 millions snapshots, which is actually nothing compared to 436 billion pages collected by Wayback Machine. However in our experience, Screenshots covered snapshots of many of the popular websites quite well. They had many snapshots of blogs, but not so many of business websites.
Although, snapshots for average websites that have been created hardly a year ago and don’t have much presence were not archived by Screenshots. On the other hand, Wayback Machine showed their complete history. So we guess Screenshots is best when you want to check history of popular websites.
Practical Use
Using Screenshots is dead simple, you either browse snapshots of featured images based on news, popularity and frequency of updates or search for a particular website in the search bar. While searching, make sure you enter complete address, for example “beebom.com” not “beebom”.
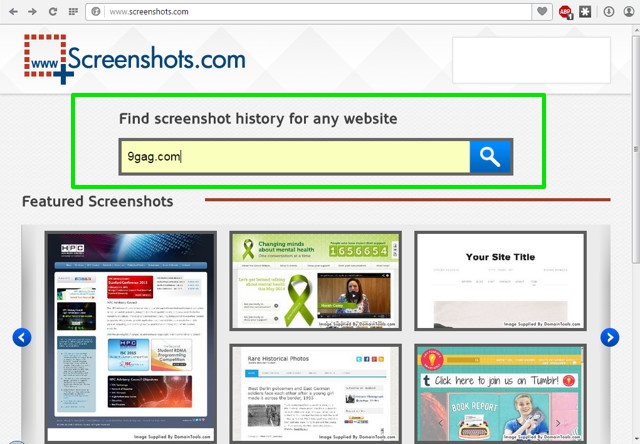
When you will search, you will find all the snapshots in a horizontal pane with a blue slider below it. You will find the latest snapshot taken date at the left of the pane and oldest on the right.
To search snapshots, just start moving the slider from left to right and you will see all the snapshots with the date they were taken, below them. Clicking on the snapshots will show a preview of them below.
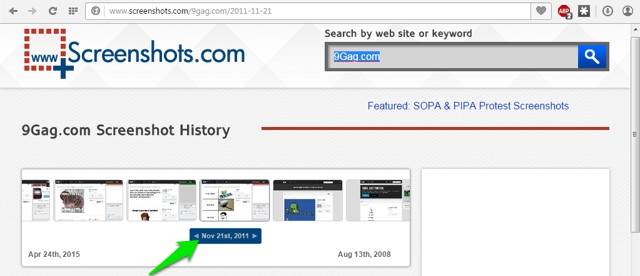
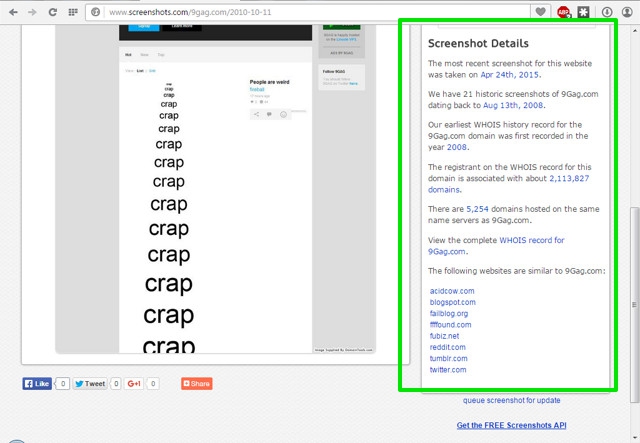
You will see all the details about the website you searched for in the right panel to the Preview window. The details include, latest and oldest screenshots date, total number of screenshots, WHOIS first history record for the domain, total number of domains on the same hosting and link to complete WHOIS record of the website. You will also find some similar websites that you may like to checkout.
Key Features: Takes screeshonts instead of copying code, easy to use with simple interface and provides complete WHOIS record of the domain.
Cons: Takes screenshots less frequently and doesn’t archives less popular websites.
Принцип работы веб-архива
Прежде чем пытаться восстанавливать сайт из веб-архива, необходимо понять принцип его работы, который является не совсем очевидным. С особенностями работы сталкиваешься только тогда, когда скачаешь архив сайта. Вы наверняка замечали, попадая на тот или иной сайт, сообщение о том, что домен не продлен или хостинг не оплачен. Поскольку бот, который обходит сайты и скачивает страницы, не понимает что подобная страница не является страницей сайта, он скачивает её как новую версию главной страницы сайта.
Таким образом получается если мы скачаем архив сайта, то вместо главной страницы будем иметь сообщение регистратора или хостера о том, что сайт не работает. Чтобы этого избежать, нам необходимо изучить архив сайта. Для этого потребуется просмотреть все копии и выбрать одну или несколько где на главной странице страница сайта, а не заглушка регистратора или хостера.
Качаем сайт с web.archive.org
Процесс восстановления сайта из веб-архива я покажу на примере сайта 1mds.ru. Я не знаю что это за сайт, я всего лишь знаю что у него в архиве много страниц, а это значит что сайт не только существовал, но с ним работали.
Для того, что бы открыть архив нужного сайта, нам необходимо пройти по такой вот ссылке:
http://web.archive.org/web/*/1mds.ru
На 24 ноября 2018 года, при открытии этой ссылки я обнаружил вот такую картину:
Как видите на главной зафиксировались результаты экспериментов с программной частью. Если мы просто скачаем сайт как есть, то в качестве главной будет именно эта страница. нам необходимо избежать попадания в архив таких страниц. Как это сделать? Довольно просто, но для начала необходимо определить когда последний раз в архив добавлялась главная страница сайта. Для этого нам необходимо воспользоваться навигацией по архиву сайта, которая расположена вверху справа:
Кликаем левую стрелку ибо правая все равно не активна, и кликаем до тех пор, пока не увидим главную страницу сайта. Возможно кликать придется много, бывает домены попадаются с весьма богатым прошлым. Например сайт, на примере которого я демонстрирую работу с архивом, не является исключением.
Вот мы можем видеть что 2 мая 2018-го бот обнаружил сообщение о том, что домен направлен на другой сайт:
Классика жанра, регистрируешь домен и направляешь его на существующий дабы не тратить лимит тарифа на количество сайтов.
А до этого, 30 марта, там был вообще блог про шитье-вязание.
Долистал я до 23 октября 2017-го и вижу уже другое содержимое:
Тут мы видим уже материалы связанные с воспитанием ребенка. Листаем дальше, там вообще попадается период когда на домене была всего одна страница с рекламой:
А вот с 25 апреля 2011 по 10 сентября 2013-го там был сайт связанный с рекламой. В общем нам нужно определиться какой из этих периодов мы хотим восстановить. К примеру я хочу восстановить блог про шитье-вязание. Мне необходимо найти дату его появления и дату когда этот блог был замечен там последний раз.
Я нашел последнюю дату, когда блог был на домене и скопировал ссылку из адресной строки:
http://web.archive.org/web/20180330034350/http://1mds.ru:80/
Мне нужны цифры после web/, я их выделил красным цветом. Это временная метка, когда была сделана копия. Теперь мне нужно найти первую копию блога и также скопировать из URL временную метку. Теперь у нас есть две метки с которой и до которой нам нужна копия сайта. Осталось дело за малым, установить утилиту, которая поможет нам скачать сайт. Для этого потребуется выполнить пару команд.
- sudo apt install ruby
- sudo gem install wayback_machine_downloader
После чего останется запустить скачивание сайта. Делается это вот такой командой:
wayback_machine_downloader -f20171223224600 -t20180330034350 1mds.ru
Таким образом мы скачаем архив с 23/12/2017 по 30/03/2018. Файлы сайта будут сохранены в домашней директории в папке «websites/1mds.ru». Теперь остается закинуть файлы на хостинг и радоваться результату.
Что такое веб-архив
Веб-архив сайтов позиционируется как своеобразная бесплатная машина времени, позволяющая вернуться на месяцы или годы назад, чтобы увидеть, как выглядел ресурс на тот момент. При этом у каждого сайта сохраняются многочисленные версии от разных дат, которые зависят от посещений проекта краулерами веб-архива. У популярных сайтов может сохраняться тысячи версий, которые обновлялись ежедневно множество раз на протяжении всего периода существования проекта:
Веб-архив основан в начале 1996 года и с этого времени в нем сохранено более 330 миллиардов веб-страниц, включая 20 миллионов книг, 4,5 миллионов аудиофайлов и 4 миллиона видео, занимающие свыше тысячи терабайт. Ежедневно сайт посещают миллионы пользователей, и он входит в ТОП-300 самых популярных проектов мира.