7 best wayback machine alternative (internet archive website)
Содержание:
- Alexa
- The Ghosts of Pages Past 1: Why Might You Use Wayback Machine?
- Page Freezer
- mydrop.io
- But What if a Page I want to See is not in the Archive?
- Method 2: using FTP
- Качаем сайт с web.archive.org
- Поиск сайтов в Wayback Machine
- Инструкция по ручному удалению рекламного вируса WAYBACK MACHINE
- Detailed comparison
- Как избавиться от рекламы WAYBACK MACHINE в Chrome/Firefox/Internet Explorer/Edge?
- Archive.is
- Блокировки[править | править код]
- Archive.is – Webpage Archive
- archive.md
- DomainTools
- Archive-It
Alexa
Alexa is well known for checking website ranking, keyword research, and competitive analysis. But it is also one of the best Internet Archive Wayback Machine alternatives which you can use to view the archived state of any website.
The user-friendly interface of this website makes it very easy for one to use it and find out what they are looking for.
Owned by Amazon.com, Alexa provides complete information about a website that includes domain information, how old the website is, links, referring domains to the website and much more.
You can even find out the browsing details and past history of any website using Alexa. Clicking on “How did example.com look in the past?” will redirect you to http://web.archive.org to see the calendar view maps (the number of times a particular site has crawled by the Wayback Machine, not how many times the site was actually updated).
If you want to see detailed information about any website, you need to create a free account on Alexa. In short, we can say that Alexa is one of the most reliable Internet Archive Wayback alternatives for everybody.
Do you know? How to Download Movies from Hotstar on Android and Computer
The Ghosts of Pages Past 1: Why Might You Use Wayback Machine?
What we’re gonna do right here is go back, way back, back into time.
Looking at Site Changes
The first reason you’d use Wayback Machine is to look at old versions of pages within a site.
This is useful for several reasons.
- You may have deleted a page accidentally from your site and need to reinstate it but don’t have a backup. You can possibly use Wayback Machine to recreate your lost page… if it is in the archive!
- If you’ve seen a visitor decrease to certain pages you might check to see if it’s because you changed something. You could use the Archive to look at the page and compare it to the current version.
- You might need proof that a detrimental change made in the past had nothing to do with you. Wayback Machine could prove that the change was made prior to you having access to the site.
- Wayback Machine could demonstrate your link building activities to clients. You could use it to show archived pages on sites where your inbound links appear after a certain date.
Looking at robots.txt
The Wayback Machine doesn’t only crawl and archive web pages as you can see in the pie chart above. It will also archive other file types on your domain such as your robots.txt file.
Looking at an archived version of robots.txt might give you pointers if you are having search engine crawlability problems. You could look at a past version of it to determine if any change you made caused the issues.
Checking for Intellectual Property Infringements
Let’s say you’ve seen that someone has been blatantly and illegally trading off your protected trademarks. Or maybe they’ve plagiarised your valuable intellectual property.
You may have sent a cease and desist asking the offenders to remove your intellectual property from their site.
The guilty party may have ignored your legal threats completely, so you decide upon the potentially costly path of litigation.
Your lawyer sets things in motion and all of a sudden your intellectual property disappears from the offending site to “bury the evidence”.
Wayback Machine might be able to show snapshots of the pages on their site where the infringement was committed. This would prove beyond dispute that you have been wronged.
Looking at How a Site Has Changed Over Time
If you take on a new client and want to understand how their website has evolved, Wayback Machine might be the perfect place to provide an overview.
The archive could show you technical changes made or even tell you a story of how the company has developed.
You could even use Wayback Machine in your preparation to pitch to a new client for their business. This might help you demonstrate a deeper appreciation of their story than your competitors who are also pitching.
Looking for Changed URL Structures
The URL structures for a site you manage for a client changed a while back. The organic traffic to the site fell sharply as a result. These changes weren’t documented and so nobody knows how to revert them.
In this scenario you might be able to use the archive to check URL structures and either reinstate them or set up redirections correctly.
N.B. If you’ve noticed decreased visits in Google Analytics, you can identify your historical URL structures there too.
Looking at the Historical Information Architecture of the Site
The archive might be able to show you how a website was organised in terms of the page or category hierarchy. It could even demonstrate the previous navigation structure.
This could be extremely useful when trying to understand whether categories or pages have been merged at some point. Equally it could present you with a better understanding of how past navigation structures have impacted conversion rates.
Page Freezer
Page Freezer is an extremely easy-to-use web and social media archiving service that automatically archives all your website content. This popular alternative to Wayback Machine is used by both webmasters and internet users as webmasters can use it for automatic archiving of web pages and users can find out the archived version of websites that are present on the internet.
The user-friendly interface of Page Freezer makes it very easy for one to see the archived version of the web pages of a website. The only problem with this Internet Wayback Machine alternatives is that you will have to login in order to see the archived web pages or protect your website records.
mydrop.io
(реф. ссылка)
Удобный сервис, кроме фнкционала восстановления контента сайта имеет фунционал поиска доменов по различным параметрам. Пользуюсь им больше года.
Из преимуществ:
- широкий набор фильтров для поиска домена
- возможность подписки на фильтр
- информативная таблица доменов с полезными seo метрикам( TF, CF, DA, PA, LinkPad, SimilarWeb, LiveInternet, Alexa)
- показывают кол-во файлов, которые восстановить и размер в МБ
- показывают, есть ли ставки на домен через сервис expired.ru
- Есть своя Cms
- адекватные цены
- скидки при пополнении счета от 3000 руб.
- интерфейс на русском
Из минусов:
- нет пробного периода либо бесплатного восстановления, если восстонавливаемый сайт «небольшой»
- есть функционал предварительного просмотра, но он очень сыроват и на счета должна быть сумма не меньше чем стоимость восстановления
But What if a Page I want to See is not in the Archive?
Firstly… don’t panic!
It would be a pain a page you wanted to examine was not in the archive. Especially if you wanted to do some of the research I’ve discussed above. The Wayback Machine homepage has a tool that you can use to snapshot a page immediately though. Of course this won’t help to examine a particular issue in the past. But you could at least start archiving the site so it’s available in future.
Type the page URL into the “Save Page Now” box and Wayback Machine will add it to the archive immediately.
The tool will save the page along with any images and CSS it finds there. However, it will not crawl any links it finds on the page and so will not archive the whole domain.
You can add more pages to the archive from a site, but you have to use the “Save Page Now” tool for each one.
If you have concerns about privacy, archive.org does not retain IP addresses on submissions you make to it. So whenever you use the tool your activity is anonymous.
One final note. When a page is archived there is no guarantee when it will be snapshotted again. So you might return to the site again and see only the version that you submitted. Having said this, Wayback Machine will revisit archived pages at some point and the calendar will show this.
Method 2: using FTP
This Tutorial explains how you can recover a website from the Waybackmachine. It also explains exactly how you can upload the files with Cpanel and FTP.
- 1. Download the .zip file with all the HTML files. Extract the files (unzip) to a folder of your choice.
- 2. You need to transfer the files to the server using FTP software. If you don’t have an FTP client already, then we recommend FileZilla: https://filezilla-project.org/
-
3. If you don’t already have an FTP account at your hosting provider, then create one. If your host uses cPanel, then find the icon that says «FTP Accounts» (most hosting providers use cPanel: Hostgator, Godaddy, BlueHost : all of them use cPanel)
cPanel example:It’s usually easier to create an FTP account when adding a domain to your hosting:
- 4. Find the IP address of your server. In GoDaddy you can find your IP address on the hosting dashboard:
-
5. We use FileZilla for Windows in this guide, but you can also download it for Apple computers.
You should now have an FTP account and know your IP address. Open an FTP client. We use FileZilla in this guide.
— Fill in your username and password.
— The username should be
— Host should be the IP address of your server, that will host the Wayback files.
— Port can be blank.
— Press Quickconnect to connect. - 6. Now select all the files and move them to the remote site:
- 7. Your site should work now.
Качаем сайт с web.archive.org
Процесс восстановления сайта из веб-архива я покажу на примере сайта 1mds.ru. Я не знаю что это за сайт, я всего лишь знаю что у него в архиве много страниц, а это значит что сайт не только существовал, но с ним работали.
Для того, что бы открыть архив нужного сайта, нам необходимо пройти по такой вот ссылке:
http://web.archive.org/web/*/1mds.ru
На 24 ноября 2018 года, при открытии этой ссылки я обнаружил вот такую картину:
Как видите на главной зафиксировались результаты экспериментов с программной частью. Если мы просто скачаем сайт как есть, то в качестве главной будет именно эта страница. нам необходимо избежать попадания в архив таких страниц. Как это сделать? Довольно просто, но для начала необходимо определить когда последний раз в архив добавлялась главная страница сайта. Для этого нам необходимо воспользоваться навигацией по архиву сайта, которая расположена вверху справа:
Кликаем левую стрелку ибо правая все равно не активна, и кликаем до тех пор, пока не увидим главную страницу сайта. Возможно кликать придется много, бывает домены попадаются с весьма богатым прошлым. Например сайт, на примере которого я демонстрирую работу с архивом, не является исключением.
Вот мы можем видеть что 2 мая 2018-го бот обнаружил сообщение о том, что домен направлен на другой сайт:
Классика жанра, регистрируешь домен и направляешь его на существующий дабы не тратить лимит тарифа на количество сайтов.
А до этого, 30 марта, там был вообще блог про шитье-вязание.
Долистал я до 23 октября 2017-го и вижу уже другое содержимое:
Тут мы видим уже материалы связанные с воспитанием ребенка. Листаем дальше, там вообще попадается период когда на домене была всего одна страница с рекламой:
А вот с 25 апреля 2011 по 10 сентября 2013-го там был сайт связанный с рекламой. В общем нам нужно определиться какой из этих периодов мы хотим восстановить. К примеру я хочу восстановить блог про шитье-вязание. Мне необходимо найти дату его появления и дату когда этот блог был замечен там последний раз.
Я нашел последнюю дату, когда блог был на домене и скопировал ссылку из адресной строки:
http://web.archive.org/web/20180330034350/http://1mds.ru:80/
Мне нужны цифры после web/, я их выделил красным цветом. Это временная метка, когда была сделана копия. Теперь мне нужно найти первую копию блога и также скопировать из URL временную метку. Теперь у нас есть две метки с которой и до которой нам нужна копия сайта. Осталось дело за малым, установить утилиту, которая поможет нам скачать сайт. Для этого потребуется выполнить пару команд.
- sudo apt install ruby
- sudo gem install wayback_machine_downloader
После чего останется запустить скачивание сайта. Делается это вот такой командой:
wayback_machine_downloader -f20171223224600 -t20180330034350 1mds.ru
Таким образом мы скачаем архив с 23/12/2017 по 30/03/2018. Файлы сайта будут сохранены в домашней директории в папке «websites/1mds.ru». Теперь остается закинуть файлы на хостинг и радоваться результату.
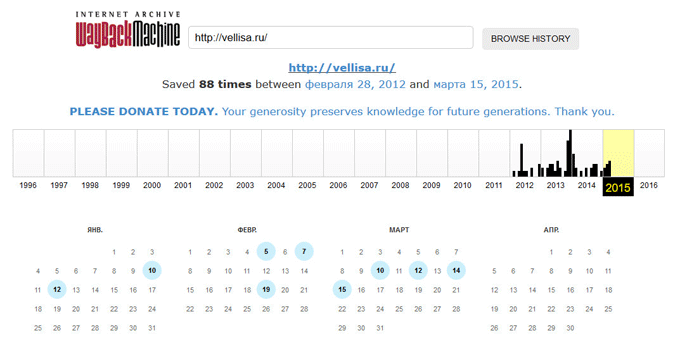
Поиск сайтов в Wayback Machine
Wayback Machine
На странице «Internet Archive Wayback Machine» введите в поле поиска URL адрес сайта, а затем нажмите на кнопку «BROWSE HISTORY».
Под полем поиска находится информация об общем количестве созданных архивов для данного сайта за определенный период времени. На шкале времени по годам отображено количество сделанных архивов сайта (снимков сайта может быть много, или, наоборот, мало).
Выделите год, в центральной части страницы находится календарь, в котором выделены голубым цветом даты, когда создавались архивы сайта. Далее нажмите на нужную дату.
Вам также может быть интересно:
- Советские фильмы онлайн в интернете
- Яндекс Дзен — лента персональных рекомендаций
Обратите внимание на то, что при подведении курсора мыши отобразится время создания снимка. Если снимков несколько, вы можете открыть любой из архивов
Сайт будет открыт в том состоянии, которое у него было на момент создания архива.
За время существования моего сайта, у него было только два шаблона (темы оформления). На этом изображении вы можете увидеть, как выглядел мой сайт в первой теме оформления.

На этом изображении вы видите сайт моего знакомого, Алема из Казахстана. Данного сайта уже давно нет в интернете, поисковые системы не обнаруживают этот сайт, но благодаря архиву интернета все желающие могут получить доступ к содержимому удаленного сайта.
Инструкция по ручному удалению рекламного вируса WAYBACK MACHINE
Для того, чтобы самостоятельно избавиться от рекламы WAYBACK MACHINE, вам необходимо последовательно выполнить все шаги, которые я привожу ниже:
- Поискать «WAYBACK MACHINE» в списке установленных программ и удалить ее.
Открыть Диспетчер задач и закрыть программы, у которых в описании или имени есть слова «WAYBACK MACHINE». Заметьте, из какой папки происходит запуск этой программы. Удалите эти папки.
Запретить вредные службы с помощью консоли services.msc.
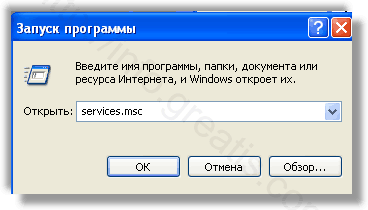
Удалить “Назначенные задания”, относящиеся к WAYBACK MACHINE, с помощью консоли taskschd.msc.
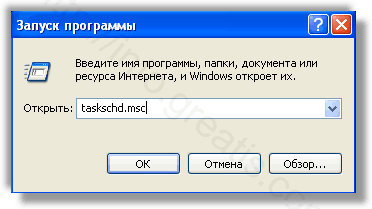
С помощью редактора реестра regedit.exe поискать ключи с названием или содержащим «WAYBACK MACHINE» в реестре.
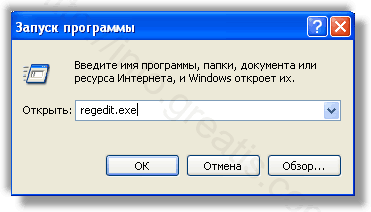
Проверить ярлыки для запуска браузеров на предмет наличия в конце командной строки дополнительных адресов Web сайтов и убедиться, что они указывают на подлинный браузер.
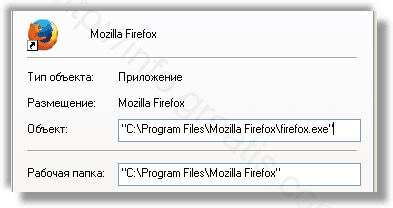
Проверить плагины всех установленных браузеров Internet Explorer, Chrome, Firefox и т.д.
Проверить настройки поиска, домашней страницы. При необходимости сбросить настройки в начальное положение.
Очистить корзину, временные файлы, кэш браузеров.
Detailed comparison
ARCHIVAL PROCESS
Full size PNG screenshotsCapture everything accurately: text, images, typography, video stills, graphs, or any other element.
HTMLMainly text and images are archived. Dynamic content may be missing.
AD SUPPORT
Yes, Stillio captures website ads.
No, website ads are not supported.
ARCHIVE SCHEDULING
Fully customizableHourly, daily or weekly or any frequency to have screenshots captured.
UnknownNo fixed capture frequency.
AUTOMATED ARCHIVING
Yes
No
REMOTE STORAGE
Yes, both offline and automatic sync to cloud providers like Dropbox, Google Drive and Zapier.
No
DOWNLOAD SUPPORT
Yes, monthly zip download available.
No
No
GEO SPECIFIC SCREENSHOTS
Yes, see the countries we support.
No
PRICING
Starts from $29, Try for Free!
Free
Как избавиться от рекламы WAYBACK MACHINE в Chrome/Firefox/Internet Explorer/Edge?
Я на этом деле конечно уже собаку съел, так что трудностей не возникло. Но прежде, чем закидывать вас инструкциями, давайте повторим сами себе, с чем имеем дело.
Это обычный рекламный вирус, коих стало пруд пруди. И имен у него много: может быть просто WAYBACK MACHINE, а может с дописанной строкой после имени домена WAYBACK MACHINE. В любом случае вирус закидывает вас рекламой, и про ваше любимое казино Вулкан не забывает. До кучи он заражает и свойства ярлыков браузеров.
Кроме того, вирус обожает создавать расписания для запуска самого себя, чтоб жизнь медом не казалась. В результате его деятельности вы вполне можете случайно кликнуть на нежелательную ссылку и скачать себе что-нибудь более серьезное.
Поэтому данный рекламный вирус следует удалять как можно быстрее. Ниже я приведу инструкции по избавлению от вируса WAYBACK MACHINE, но рекомендую использовать автоматизированный вариант.
Archive.is
Archive.is is another good alternative to Wayback Machine and arguably better than Screenshots for most people. It is not one of the most attractive websites or easy to navigate, but its database and archiving methods makes up for it.
Archive.is will let you both search for website history and let you take a screenshot of any domain on demand, which will be saved for everyone to see. This makes it a perfect solution to get all the details about a website, including data and graphical details.
How it Works
Archive.is archives a website on demand or according to the frequency of the activities on a particular website. It will take both screenshot and code of a website while archiving. However, unlike Wayback Machine it doesn’t sends crawlers to archive web pages. This means a website can’t stop Archive.is from archiving using a robot.txt file.
If there is a website that may be blocking Wayback Machine from crawling its site, then you should opt for Archive.is to get a peek.
Practical Use
The website of Archive.is is not nearly as attractive as Wayback Machine or Screenshots. Although, it is quite simple to navigate with least options to worry about. On the main page, you will find two search bars, one in red at the top and other in blue at the bottom. Red search bar is where you can demand archiving of a web page, and in the blue, you can check the history of any website.
Demand Archive
In the red search bar, you can demand archiving of any website and Archive.is will copy code and take a screenshot of it. Just enter the URL of the website page in the search bar, and click on “save the page”.
Archive.is will start processing and after a short delay (depending on the page size), you will see the archived page and a screenshot of it.
Note: You are not limited to just adding Landing page URL of a particular website, you can add URL of any page of a website. Just access the page you want to archive and copy/paste its URL in the archive.is search, it will be archived.
Check Archived History of a Website
In the blue search bar below, you can enter the URL of a website, and you will see all its history. There will be two options, Oldest and Newest. Oldest just contains the oldest archived web page, and Newest contains the latest archived pages and going back from there.
You will see all the archived pages, starting from the latest and going backwards along with the data mentioned below each web page. You can just click on any webpage to see its details.
The archived web page will open up and you can easily scroll between it. You can click on “Screenshot” to see a screenshot of that particular web page.
You can also share the web page over social networks by clicking on “share”. The web page can also be downloaded for future reference, just click on “Download” to download the results.
In our results, Screenshots archived 9gag 21 times and on the other hand, Archive.is archived it 1063 times. You can weigh the frequency of archiving website with this little example.
Key Features: Archives both code and screenshot of a web page, huge database, share & download results, and request for archiving of any website any time.
Cons: Unattractive interface, hard to navigate to reach the required web page and doesn’t provide much information about a particular web page.
SEE ALSO: 40 Cool And Interesting Websites
Блокировки[править | править код]
В 2015 году Роскомнадзор принял решение заблокировать Wayback Machine за копию страницы текста «Одиночный джихад в России», содержащего информацию о «теории и практике партизанского сопротивления». Соответствующая страница в Архиве Интернета была добавлена в официальный реестр запрещенных веб-сайтов в России 23 июня 2015 года, из-за чего некоторые российские интернет-провайдеры были вынуждены полностью заблокировать сайт Архива Интернета. В 2019 году представители Ассоциации по защите авторских прав в интернете (АЗАПИ) подали серию исков против сервиса Wayback Machine за нарушение авторских прав. Представители АЗАПИ запросили Мосгорсуд вынести решение о вечной блокировке портала на территории России, однако на август 2020 года Архив Интернета по-прежнему продолжал свою работу.
В 2017 году портал был заблокирован в Индии и Киргизии за содержание «экстремистских материалов». По данным на 2021 год сайт заблокирован в Китае.
Archive.is – Webpage Archive
As the name suggests, Archive.is is another best alternative to Wayback Machine. This Internet archiving website is used by thousands of users across the globe as it comes with a user-friendly interface and is quite easier to navigate.
The simple archive mode of this website will display different versions of the website as per the screenshots are taken by grabbing them from the Archive.is database. The graphs feature will show you the graphical detail of any website which lists out the Page Views generated in a month, the number of users accesses the website in a month and much more.
When you visit Archive.is site, the website displays two search bars on the homepage which can be used to store the archive of a website and even view one? This means that if you are a website owner and want to have an archive of your website, you can do that manually by visiting Archive.is.
As there are very limited but useful functions provided by the Archive.is, which makes it easier for one to access it and view the past state of any website. So, if you were looking for an easy to use Internet Archive Wayback Machine alternative then Archive.is is one of the quick ways to see old cached websites.
archive.md
Адреса данного Архива Интернета:
На главной странице говорящие за себя поля:
- Архивировать страницу, которая сейчас онлайн
- Искать сохранённые страницы
Для поиска по сохранённым страницам можно как указывать конкретный URL, так и домены, например:
- microsoft.com покажет снимки с хоста microsoft.com
- *.microsoft.com покажет снимки с хоста microsoft.com и всех его субдоменов (например, www.microsoft.com)
- покажет архив данного url (поиск чувствителен к регистру)
- поиск архивных url начинающихся с http://twitter.com/burg
Данный сервис сохраняет следующие части страницы:
- Текстовое содержимое веб страницы
- Изображения
- Содержимое фреймов
- Контент и изображения загруженные или сгенерированные с помощью Javascript на сайтах Web 2.0
- Скриншоты размером 1024×768 пикселей.
Не сохраняются следующие части веб-страниц:
- Flash и загружаемый им контент
- Видео и звуки
- RSS и другие XML-страницы сохраняются ненадёжно. Большинство из них не сохраняются, или сохраняются как пустые страницы.
Архивируемая страница и все изображения должны быть менее 50 Мегабайт.
Для каждой архивированной страницы создаётся ссылка вида http://archive.is/XXXXX, где XXXXX это уникальный идентификатор страницы. Также к любой сохранённой странице можно получить доступ следующим образом:
- http://archive.is/2013/http://www.google.de/ — самый новый снимок в 2013 году.
- http://archive.is/201301/http://www.google.de/ — самый новый снимок в январе 2013.
- http://archive.is/20130101/http://www.google.de/ — самый новый снимок в течение дня 1 января 2013.
Дату можно продолжить далее, указав часы, минуты и секунды:
- http://archive.is/2013010103/http://www.google.de/
- http://archive.is/201301010313/http://www.google.de/
- http://archive.is/20130101031355/http://www.google.de/
Для улучшения читаемости, год, месяц, день, часы, минуты и секунды могут быть разделены точками, тире или двоеточиями:
- http://archive.is/2013-04-17/http://blog.bo.lt/
- http://archive.is/2013.04.17-12:08:20/http://blog.bo.lt/
Также возможно обратиться ко всем снимкам указанного URL:
http://archive.is/http://www.google.de/
Все сохранённые страницы домена:
http://archive.is/www.google.de
Все сохранённые страницы всех субдоменов
http://archive.is/*.google.de
Чтобы обратиться к самой последней версии страницы в архиве или к самой старой, поддерживаются адреса вида:
- http://archive.is/newest/http://reddit.com/
- http://archive.is/oldest/http://reddit.com/
Чтобы обратиться к определённой части длинной страницы имеется две опции:
В доменах поддерживаются национальные символы:
- http://archive.is/www.maroñas.com.uy
- http://archive.is/*.测试
Обратите внимание, что при создании архивной копии страницы архивируемому сайту отправляется IP адрес человека, создающего снимок страницы. Это делается через заголовок X-Forwarded-For для правильного определения вашего региона и показа соответствующего содержимого.
DomainTools
If you want to find out Whois information or are looking for Wayback Machine alternative then you need to give a try to DomainTools screenshots lookup. As the name of this website suggests, it is going to provide you information about a domain name for free and screenshot history as well.
This website is famous for finding out domain owner and registration information etc. However, you can also find out details such as domain history, how the website looked some time ago using Domain Tools.
The functioning of Domain tools is similar to Screenshots.com as you just have to enter the URL of the website in the search bar and it will list you all the screenshots which are available for that particular website. The database of DomainTools is updated from time to time which makes it a worthy Internet Wayback Machine alternative.
Archive-It
Do you or your organization have a website that needs to be indexed and archived frequently? If so, manually archiving each individual web page using the methods above can be incredibly tedious and costly. Fortunately, the Internet Archive provides a service called Archive-It that can automate the archiving process for you.
This service is not free; however, it can be ideal for those who want to back up their content with a “set it and forget it” mentality. Just stipulate which pages you would like to save and how often. This paid subscription is perfect for those who wish to save their web content on a regular basis.
Do you use the Wayback Machine? If so, do you visit it purely for fun or do you find it a useful tool? Are there other ways to back up content on the Web? Let us know in the comments!